Learnings about handling fraud with data and machine learning
Anomaly detectors, rule-based systems, fallback options, and common sense.

The Internet is a sea of information. Whenever you have a question, you visit Google and ask: "How to make a pancake?" "What's the best Pokemon?" "What are things I should keep in mind while dealing with fraud?" One of these is not like the other, right? At the end of the day, we all know Pikachu is going to win. Jokes asides, I would like you to read that last question and make a mental list of things you believe someone should keep in mind while using data to deal with fraud; I'll come back to the list later.
I work with moderation and data. First, it was spam prevention, and now, fraud. Dealing with fraud has been something I've always wanted to work with, so I remember spending a considerable amount of time reading about fraud moderation techniques, tips, etc. While interesting as these sources were, I realized that many of them cover similar topics and examples. And don't get me wrong; there's nothing bad with that. After all, fraud is a very particular topic. But now that I'm working in the field, I recognized that those concepts and techniques I learned are far from the reality I face in my daily work, and so, in this article, I want to share some of the details I've learned during my time using data to combat fraud. Let's go!

Try other techniques other than supervised learning
One of the most common believes I've seen about handling fraud with machine learning is that the datasets are highly imbalanced. This fact prompts many of the available resources to center the discussion around this characteristic and, therefore, focus on methods that are good at handling these cases. In my case, I've taken a liking to try unsupervised learning models, in particular anomaly detection models. I tend to formulate fraud detection problems as anomaly detection problems because fraudulent cases are a small minority and could often be seen as outliers. On top of that, with unsupervised learning, I don't have to worry about the labels.
One of my to-go algorithm from this group is Isolation Forest because it has proven to work well and fast in many use cases. To show an actual example, below is a normalized and dimensionality reduced sample of an unlabeled test dataset I used at work. With this dataset, my goal is to use the algorithm to learn in an unsupervised fashion, a function that separates the inliers from outliers. Without getting into details, I'll mention that it involves the spending of the in-app currency. On the bottom left area of the chart, we have many entries, which implies that most of the spending habits fall in this region. On the other hand, the rest of the plot's data points denote users with an unusual spending pattern.
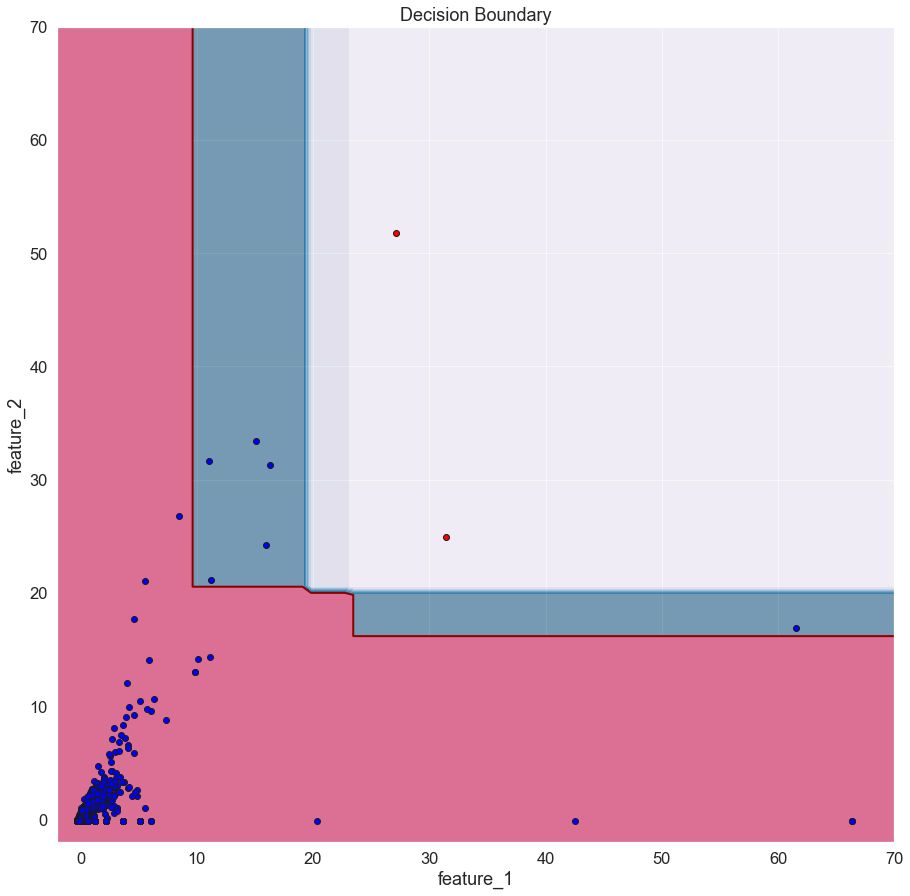
The red contour we see on the image is what I call the model's "hard" learned decision boundary—everything that's inside is considered an inlier while everything outside an outlier. However, the blue contour is the "soft" decision boundary, an area where the outlier values aren't as extremes as those in the red part.
Another technique I found useful is the rule-based systems. Yes, that's right. As restrictive or limited as they could be, a well-prepared, handcrafted, and data-driven rule-based system consisting of if's and else's could allow us to detect fraudulent events while minimizing the risk of making a wrong decision. Furthermore, they are simpler to explain than an ML model. But of course, they are far from perfect. To build one, the responsible person needs to be well aware of the domain since they can be quite complex to tweak (that's why we use machine learning, right?).
For example, suppose that you want to build a rule-based system to create a decision boundary manually using the dataset presented above. In this case, it shouldn't be that complex since we are dealing in a two-dimensional space where the outlier or possible fraudulent cases are well-defined. But what if we would have a messier and more complex dataset? If so, building such a rule system could be very time-consuming. To aid with the development of rule-based systems, I've been experimenting with a Python package named human-learn, which, and I quote the official documentation, "make it easier to construct and benchmark rule-based systems that are designed by humans."
My favorite—and probably the coolest—human-learn feature is that it let you interactively draw with your mouse (yes, draw!) the decision boundary on a plot. For example, in the image below, I'm defining the "rules" by drawing a decision boundary in the desired area.
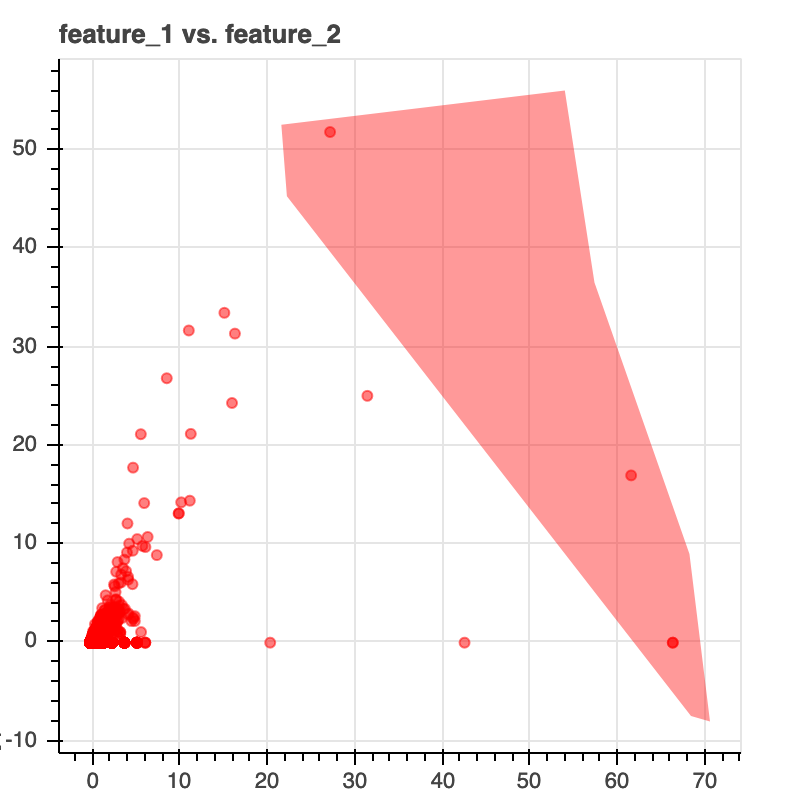
After setting the rules, I'm using an InteractiveOutlierDetector object to create a scikit-learn-like model to train and predict as if it were one (using the fit() and predict() methods, respectively). The following image is the same dataset with the predictions obtained from the model (the outliers are the same as above because I predicted using the training set). Below is the code I used for my human-learn model. The tool is not mainly made for handling unlabeled or one-class cases, so I had to modify my DataFrame to make it work.
import matplotlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from hulearn.experimental.interactive import InteractiveCharts
from hulearn.outlier import InteractiveOutlierDetector
# Set the Seaborn looks
sns.set(font_scale=1.5)
X_train = pd.read_csv('data.csv')
X_train['label'] = '0'
X_train = X_train.rename(columns={"mean": "feature_1", "sd": "feature_2"})
charts = InteractiveCharts(X_train, labels="label")
# This loads the interactive chart.
charts.add_chart(x="feature_1", y="feature_2")
model = InteractiveOutlierDetector(json_desc=charts.data())
# Remove the labels from the DataFrame add it to
# a second variable.
X, y = X_train.drop(columns=['label']), X_train['label']
preds = model.fit(X, y).predict(X)
plt.title('Predictions using the hand-crafted model\nWhere red are the outliers and blue the inliers')
plt.scatter(X['feature_1'], X['feature_2'], c=preds, edgecolors='k',
cmap=matplotlib.colors.ListedColormap(['blue', 'red']))
plt.xlabel('feature_1')
plt.ylabel('feature_2')
plt.grid(True)
plt.show()
Always have a fallback option
But rule-based systems can be more than that. Even if you don't use them as your primary decision-making module, they could serve quite well as a fallback or double-check option for cases where we should debate over the ML model's decision.
When dealing with spam and fraud, I learned that we should not blindly apply the model's output because there's model prior knowledge or decision that must come first; this is where domain knowledge shines.
To handle this, I resorted to building numerous "safety net" mechanisms that double-checked my "true" predictions ("spammer" or "fraudster") before taking action to avoid certain situations from happening.
In a fraud setting (and many others), such measures are suitable for preventing possible false positives or intended cases. For instance, you wouldn't be so happy if your bank blocks your account if you do X or Y transaction. However, if you call them beforehand, they might put a flag on the account and "ignore" any transaction that otherwise might seem fraudulent. Or hypothetically speaking, suppose that during analysis, you discovered that most users who have feature X and Y and are classified as fraudulent are typically false positives. In this case, add a small module that checks for these features. Remember that your opinion and knowledge is as essential as that of the model.
Not all anomalous cases are bad
In the first point, I said that I treat many of my problems as anomaly detection ones. So, it is easy to interpret these detected anomalies as something "bad" (which makes sense considering the term "anomaly" might convey a negative feeling). But this is not always true—anomalies could also be good! For example, a sudden surge in activity could either mean more activity caused because of a promotion (which is excellent) or a spam wave (which is not ideal at all). But how do we separate the good anomalies from the bad ones? How should we treat them, particularly in a production system where everything is automatic? Well, an option is the rule system from above.

Preventing the fraudulent event before it even happens
Before getting started here, I'll admit that detecting the fraudulent event before it occurs is not always an option. That's because there are cases in which there are no incoming signals before the fraudulent action is executed or because there's no way to do it because of the way the platform is built. And so, we would essentially be blind until the fraud happens.
However, if this is not the case, then I propose—no— I encourage you to try to prevent the fraud before it even happens. Maybe I sound a bit biased because this was a strategy back when I dealt with spam, but wouldn't it better to avoid the consequences from happening in the first place? For example, I'm willing to say that most platforms with a feature that prevents users from sending nude images first scan the image for any sort of nudity and then allow it to reach the destination if it is clean.
But how could we prevent a fraudulent event and detect it before it happens? There could be a million ways, which, again, depends on the design of the platform. For instance, in an event-based setting, you could have a classifier that predicts whether the user is "fraud" based on the sequence of the events it executes and another model that uses the same sequence to predict the likelihood of the next action being fraudulent.
Recap
As with most things machine learning, fraud detection is a non-trivial topic that requires more than knowing machine learning algorithms to tackle it. Therefore, it helps to think about the problem from an out-of-the-box perspective and apply unconventional methods and solutions that could help us solve them. In this article, I've discussed four different strategies I've used during my time trying to moderate fraud, many of them which I learned from my time working with spam. However, as I mentioned early in the article, we need to understand that no solution compatible with every case and that every now and then, we will surely fail. Yet, I'd invite you to consider them and reflect on if or how they could help you.
At the beginning of the article, I asked you to do a mental list of things one should keep in mind would consider when applying machine learning to a fraud-related dataset. Did you do it? Did any of my points make your list? Share yours with me! I'd love to hear it and, even better, see how I could apply them.
Thanks for reading.
Featured photo by Will Myers on Unsplash.