Sorry, but your cat or dog AI is damaging the world.
Summarizing the “Green AI” paper

The AI field is changing the world. Since its resurgence early this decade, we have felt the impact and effect that such technology is having in our daily lives, business world, and computing panorama. At its beginning, we associated AI and its child, machine learning, with Netflix’s and Amazon’s recommendation systems or with models whose purpose is predicting whether this is spam or not. However, the situation has changed. AI has evolved so much up to the point that it’s sliding into other facets of our lives. For example, self-driving cars are unquestionably one of its main achievements. But as the field keeps growing and advancing, so are the requirements and computing power needed to train and maintain these systems. And while these platforms and services are shaping our future, unfortunately, their high power requirements are taking a toll on the environment.
On July 2019, Roy Schwartz, Jesse Dodge, Noah A. Smith, and Oren Etzioni from the Allen Institute for AI, Carnegie Mellon University and the University of Washington released a paper titled “Green AI.” In the publication, the authors advocate for what they named, Green AI, a kind of artificial intelligence research, and methods that are environmentally friendly and inclusive. In particular, the authors propose using efficiency, alongside accuracy and overall performance, as an evaluation metric for future AI implementations. Furthermore, the writers suggest that Green AI could turn the field into a more inclusive one. By doing so, not only researchers but students and others that don’t have access to state-of-the-art machines would have the opportunity to contribute to the field.

Red AI
According to the paper, the opposite of Green AI is Red AI. That is, “AI research that seeks to obtain state-of-the-art results in accuracy (or related measures) through the use of massive computational power — essentially “buying” stronger results.” Regarding this, they say that even though research is resulting in better and more accurate machine learning models, the actual gain is at best logarithmic. In other words, the benefit is not that significant when we consider the number of resources that science is pouring in. Here, resources refer to three different factors. The first one being the quantity of training data that goes into the model, which affects the length of the training stage. Then, there’s the model’s execution cost on a single example (either to train the system or to predict an outcome). Lastly, the last resource they mention is the number of experiments or iterations a model undergoes until it finds an optimal set of hyperparameters, which are the knobs one turn around to tune a model. With these three components as a base, the authors developed an equation that grows linearly with them. It looks like this:
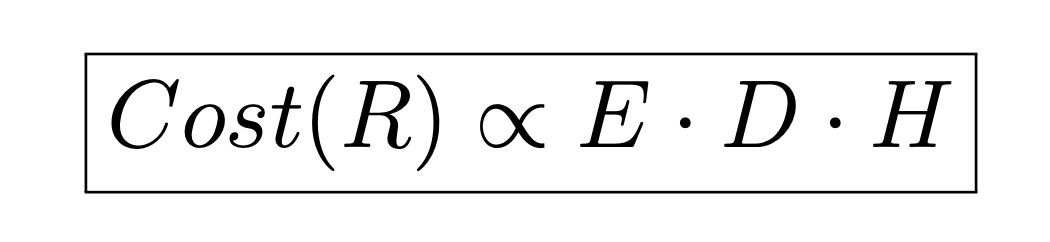
In simple words, it means that the general cost of developing a machine learning model is proportional to the product of processing a single (E)xample, times the size of the training (D)ataset times the number of (H)yperparameters trials. But why these particular values and not others? The authors add to this. The first component, E, relates to the expense linked to the vast amount of resources needed to either train or maintain a large neural network model. For example, at some point, the costs of well-known AlphaGo, a system that plays Go, is around $1000 per hour (source), while others, such as Grover model, used for detecting fake news required over $25,000 for training it (source).
Likewise, the second part of the equation, D, which refers to the size of the training set, explains that the current trend of employing bigger datasets adds to the computational cost of the system. Regarding this, they comment that training AI entities like FAIR’s RoBERTa language model required around 25000 GPU hours due to its large training corpus of 40 billion words (source). Then, there’s the last element, H. This one describes the number of experiments a project goes through before its final version is released. For instance, one Google project has been trained on over 12000 different architectures (source). The authors state that this value is usually not reported.

Green AI
The equation and concepts presented in the previous section point out different measures that could be considered if one wishes to reduce the cost and resources needed to train a machine learning model. Nonetheless, these values don’t tell the whole story and do not describe precisely how green an AI is. As a result, the authors introduce various green measures of efficiency that could be used as evaluation metrics to quantify the environmental friendliness of an AI.
The first of these measures is the direct carbon footprint produced by the model. However, realistically speaking this measure is quite unstable due to how dependent it is to the electricity infrastructure. Thus, it wouldn’t be possible to use it to compare performance across models. Similar to this score is the electricity usage of the model. Unlike the carbon footprint, electricity usage is more accessible since most GPU and CPUs report the electricity consumption ratio. However, this usage value is very dependent on the hardware. Thus, once again, it is not practical to use it to compare different models. Another efficiency measure is the training time. And while this is one is very direct and can quickly tell how efficient and green an AI is, like the previous one, it’s also very dependent on the hardware.

Two others measures, albeit more technical, are the number of parameters, and the floating point operations(FLOP). The former one relates to the bits and bobs that make an algorithm learn; in other words, they are the learned “things.” What makes this measure an appropriate one is that the number of parameters correlates directly to the memory consumption of the model, and hence, it relates to the amount of energy it requires. Nonetheless, it’s not perfect, and this is due to the architectural design of the model. So, even if two models have a similar set of parameters, their shapes will dictate how the amount of work they do.
Lastly, we have what the authors call a concrete measure, the floating point operations. The FLOP defines the number of basic arithmetic actions performed by the model, giving an estimation of the total amount of work done by it and its energy consumption. Moreover, another useful property of FLOP is that is it completely independent of the hardware, so, it is suitable for making fair comparisons across models. FLOP is not perfect, though. For instance, one model can have different implementations, so even if two architectures are the same, the amount of work they do is directly linked to the framework underneath the neural network. Currently, they are some libraries that calculate the FLOP of a system, and there are even papers that report their values. However, the authors state that this is not an adopted practice.
So, what can we do about this?
Across the whole paper, the author refers to large, complex, and expensive models produced by big names such as Google. But where does that leave the rest of us? As a data practitioner and machine learning engineer, I’ll pitch in and say that we can also make a difference.
For starters, when developing a new model, we should keep in mind the equation authored in the paper and consider each of its components. While at it, we should question ourselves and determine if some of the needed parts of developing an ML system — for example, a massive dataset — are crucial to the performance we want to achieve. Even more drastic, we need to consider if we should train this model at all. For example, does the world really needs another cat or dog classifier? There’re tons of them out there; grab one and go with it. Likewise, there are techniques like transfer learning, in which one can reuse a model trained for one task as the starting point of another one; this method can drastically decrease the training time. Then, there is the lite version of many models. While they are not as accurate as their heavy counterparts, they are can very fast and efficient, e.g., MobileNet. Now, don’t get me wrong. I’m not saying that we should disregard the heavy models and stoping doing “red AI.” Never! There are critical cases, such as disease diagnosis and self-driving cars, that require the top state-of-the-art models.

As a takeaway, I want to say that we, the data community, should be more aware of the impact we are producing in the environment. To further spread the voice, and encourage others, we can start taking small steps such as measuring the models with the metrics stated above and document the results. There’s no need to say that AI is here to stay. Its models and products will be getting better, stronger, and hunger. So, I truly believe that are we just scratching the surface of this red and green AI phenomenon.
Thanks for reading.
Pineapple picture by Pineapple Supply Co. on Unsplash.