Building a League of Legends team recommender in Go
How to build a recommender system from scratch, and deploy it in the cloud
Ever since the boom of machine learning started, many aspects of our online lives have become a target of it. In particular, one of its primary use cases — recommender systems — have become so prevalent in our lives that sometimes we forget they are there. These smart platforms attempt to recommend us something — that in many circumstances we don’t even know it exists — based on other things we have previously interacted with, i.e., purchased, selected, seen. Everyday activities such as shopping, choosing what to eat, and browsing a movie library are some of the tasks enhanced by the power of smart recommendations.
Despite having recommender systems looming several facets of our digital presence, an area that remains more or less untouched by it is the field of video games.
As of today, some authors and researchers have written and developed papers and projects regarding recommendation systems for games. Most of them explore concepts such as how likely a person is to purchase a game based on its previous choices of games, e.g., someone who likes Pokemon could like Mario or choices based on characteristics and concepts, e.g., a person who enjoys sports would probably like the newest basketball or football game. The detail about these projects is that they are built around video games as a product, as a something you buy, more alike to a system that recommends a movie, and none of them are an implemented feature of the game itself.
Long are the days in which games were a simple piece of software that you turn in, beat the story and move on. Games today have become more complex, connected and social. With the term complex, I refer to the high level of decision-making choices a player has to take within the game. With connectivity, I am alluding to the fact that every day more games are “online-only” and even offer purchases, ads and implement the business model known as games as a service. Lastly, games today are more social — there are games in which you have a hundred players in the same section, massively online games in which thousands of users share a world, and even games that let us take its experience to other external platforms such as a proprietary social-like hub.
Mixing these three properties result in an environment we could consider a generator of data. Situations such as the decisions a player take within a game, or each of the teammates a player participates with, and every outcome of a match is a data point we can keep track of, analyze, and ultimately, learn from it.
In this article, I introduce a recommender system I built from scratch written in Go for the game League of Legends (LoL). LoL is a multiplayer online battle area game (MOBA) which features two teams made of five players each (in its default mode) competing against each other. In layman’s terms, we could summarize the game’s goal into the following sentence: each team has to reach the other team’s hub (known as the Nexus) and destroy it before the opposing team slays yours. This task is not an easy one since each side has defensive structures, items, and minions that hinder every step you make. However, the real complexity of LoL lies in the fighters, or Champions as they called in the game.

League of Legends has 141 champions (at the time of the experiment), and none of them is perfect; they have weaknesses, strengths, some excels at some tasks while some of them are horrible at others. At the beginning of each match, each player has to select its champion. However, there are specific rules regarding the selection of champion in a game, with the more crucial one being that no champion can be duplicated, meaning that only one instance of each champion is allowed. There are some rare exceptions to this rule, and even more restrictions, such as the order in which each player selects its champion, but for the sake of simplicity (and in this first version of the project), the system won’t consider these cases.
The recommendation system I created, deals with those champions, and its purpose is to recommend a complete team composition, that is the five champions each player should choose. Moreover, besides having just a recommendation system, my goal was to build a complete program that also serves the recommendations via a web service.
Throughout this article, I explain all the steps I took to design my system, which include the data collection process, benchmarking and the recommendation algorithm. Also, I describe how I moved the project into a Docker container and exposed the recommendations using a web service deployed in the cloud.
Oh, and I am not affiliated with Riot Games. This work presents a project I did for fun :).
The recommendations
The central vision of this project is recommending a complete team composition, that is, a team made of five different champions, for a League of Legends match. These recommendations, based on previously seen training data, should (hopefully!) be good enough to be used in a real game.
The algorithm
This system employs a neighborhood-based collaborative filtering algorithm that uses k-NN (k-nearest neighbors) to find its nearest objects. At training time, because k-NN is a lazy learner, the model won’t learn a target function. Instead, it will “memorize” data and generalize from it once a prediction request has been done to the system. At this prediction stage, the algorithm loops through every single training example from its search space and calculates the distance between them and the input feature vector. Once it has finished calculating the distances, they are sorted in descending order and the algorithm finally returns the top N items.
The algorithm’s input is an incomplete team composition, in other words, a list of champions, made of either one, two, three or four of them. The output is a complete team composition made of the five champions the algorithm thinks are the most appropriate ones. For example, the input vector [ashe, drmundo] might return [ashe, drmundo, masteryi, yasuo, zyra].
The data
I obtained the data used for training the system from Riot Games’ League of Legends API through the Python wrapper library Riot-Watcher. Getting what came to be my final dataset was not a straightforward process due to the kind of data I needed, which was team compositions of winning teams, in other words, I wanted to know which were the five champions who won a match. However, there is not a direct way of obtaining data from past random matches, except for an endpoint that returns the current ongoing featured matches. So how do we proceed from here?
The main goal here is to obtain many match IDs so that we can consequently use those IDs to obtain the information about the matches, especially the team composition and the outcome of the match (who won). My first step was to use the “featured games” endpoint to retrieve the summoner name of the players of said feature matches. Then I called the summoner (player) endpoint using the summoner name as a parameter to get its matches and the participants of them; the purpose of this is to get as many account IDs as possible. Those account IDs were then used to get more match IDs, which were finally used in the “match” endpoint to get the data I needed.
As a side note, I should mention that the Riot API has a rate limit, so the process of collecting the data took over a couple of days. I would also like to state that I did this with my best intentions. In no moment my goal was to misuse or abuse the system, so it this seems unethical, or if someone — mostly from Riot — believes I should take this explanation down, please communicate with me.
So, we finally have our data. However, it is not in useful shape, therefore as everything data-related I had to spend some time to work with my data to transform it into a dataset of N rows (each observation), and M columns, where each column represents a champion. The value of these rows is either0 or 1 if said champion was part of the team configuration. The shape of my final dataset is 110064 x 141.
The recommendation engine
Even though the recommendation algorithm is the heart of the system, several other features improve the whole engine. For starters, within the algorithm, there is the notion of distance, which is the measurement of how distance an object — a team within the model’s search space — is from another. Then, we have the concept of something I named an intercept and a serendipitous recommendation, as well as a shuffle operation. These three are enhancement techniques I implemented into the system to modify the recommendation output. Lastly, the platform also contains an abstraction layer in the shape of a web service used for serving the recommendations to users. In the next subsections, I expand on these designs.
Distances
During prediction time the algorithm computes the distances between the training examples and the given input vector to find the closest team configuration. Because this is an essential part of the algorithm, I implemented — mostly because I wanted to experiment — four different distances method that a user can select before performing the prediction. These are Euclidean and Manhattan distances, the cosine similarity and Pearson’s correlation. To the latter one, Pearson’s correlation, I modified it because I wanted to be consistent with the others and have the minimum value at zero.
Shuffle
A shuffle is an optional operation I added that shuffles the order in which the algorithm loops over the vector space to calculate the distances. Otherwise, the vector space is always traversed in the order each training example was loaded, e.g., row 1, row 2, row 3, and so on. I’ll explain why I did it in the next example.
Suppose we have dataset made of three observations: X, Y, Z (in that exact order), and that we want to get a single prediction (with k=1) for input vector I. What the system does is calculating the distance between (X, I), then (Y,I) and (Z,I).
Now imagine that the distance between (X, I) and (Y, I) is precisely the same. In such a case, after sorting the distances (as explained in the algorithm section), the algorithm always recommends the team composition X since it came before Y.
However! If we shuffle the order in which the algorithm traverses the training set, we might encounter an occasion on which the algorithm calculates first the distance between (Y, I) instead of (X, I) and in such case the recommended team is Y.
Is this useful? Hard to tell.
Intercept recommendation
With the goal of having recommendations that are easier to read and understand, I implemented something I called an intercept recommendation. Usually, by default, the output of the recommendation is a list of k team compositions, where k is the number of neighbors selected. The problem with this list is that it doesn’t directly point us at a single team which should be the best one. Instead, the user should make its final decision regarding which of the k team it should use based on its knowledge.
What an intercept recommendation does is calculating the interception across all the k recommended teams to return the champions that appear in all the k recommendations, so instead of having several possible teams, the user receives a list of the possible and most appropriate champions that should be optimal for its team.
For example, suppose that a normal recommendation with k=3 returns [1,2,3,4,5], [29,10,2,3,8] and [3,4,2,22,81]. Under an intercept recommendation, the output would be [2,3] since these champions show up in the three original recommendations.
Serendipitous recommendation
A serendipitous recommendation is a recommendation mode enhanced by adding an extra team composition — calculated at the prediction step — to the algorithm’s output. In recommendation systems, the notion of serendipity represents the idea of attaining a recommendation which could be surprising to the user, or as stated in the paper Introducing Serendipity Through Collaborative Methods, “finding something good or useful while
not specifically searching for it.”
The steps the algorithm takes to obtain the special serendipitous recommendation (after having computed the normally recommended items) are the following:
- Get the next k closest items, where k is the number of neighbors. In other words, if
k=3, then the algorithm looks for the three recommendations that followed the ones previously found (sort of usingk=6). - An array with the frequencies (number of occurrences) of all champions is built to know the count of each champion.
- Create a new recommendation using the top 5 champions according to the frequencies.
The intuition behind this feature is to increase the searching space (by rising k) to find the champions that appear the most. The main advantage of this approach is that the system is constructing an entirely new team, that otherwise couldn’t have been found, based on the frequencies. However, on the other hand, the configuration could be horrible.
Web service
One of the main goals of this project is to serve the recommendations to the outside. Thus I wrote a simple REST API that wraps the “recommend” component of the system under one endpoint. This endpoint, which I named “recommend” receives as input a JSON that should follow the following structure (this is Go code):
type PredictionInput struct {
Champions []string `json:"champions"`
Intercept bool `json:"intercept"`
Shuffle bool `json:"shuffle"`
Serendipity bool `json:"serendipity"`
}Firstly, the JSON needs a list of the champions, that is, our current team, or the team that we wish to complete using the recommendations. Besides this, the JSON accepts three bools that specify if the algorithm should compute an intercept or serendipity recommendation, or perform a shuffle.
To compile and run the service execute make run-service-local from the project’s root directory, or if you have Docker installed, the command make run-service-docker downloads the image and runs it.
While the service is running (either locally or from Docker), execute a command like this one from to obtain a recommendation.:
Cloud deployment
With the dockerized recommendation engine dockerized and a web service that serves the recommendation, my next step was to make the system accessible to everyone. Hence I opted to deploy it in Heroku, a cloud platform application.
Deploying a Docker image in Heroku is a reasonably straightforward process. After creating a new account, go to the root directory of the project (or any directory that contains a Dockerfile) and execute:
$ heroku container: login to log in to the Registry Container
$ heroku create this command names the app after a randomly generated name (mine is evening-citadel)
$ heroku container:push web -a name_of_app to push the Docker image
$ heroku container:release web -a name_of_app to release it.
For further instructions visit: https://devcenter.heroku.com/articles/container-registry-and-runtime.
My web app is available at http://evening-citadel-74818.herokuapp.com
To query it run the previous command but replacing localhost with the address. Like this:
$ curl -d '{"champions": ["ashe", "drmundo"], "intercept": false, "shuffle": true}' -H "Content-Type: application/json" -X POST http://evening-citadel-74818.herokuapp.com:80/recommendNote: the system is running on a the free-tier machine, so apologies in advance if it down or slow. Also, don’t abuse it :)
Benchmark
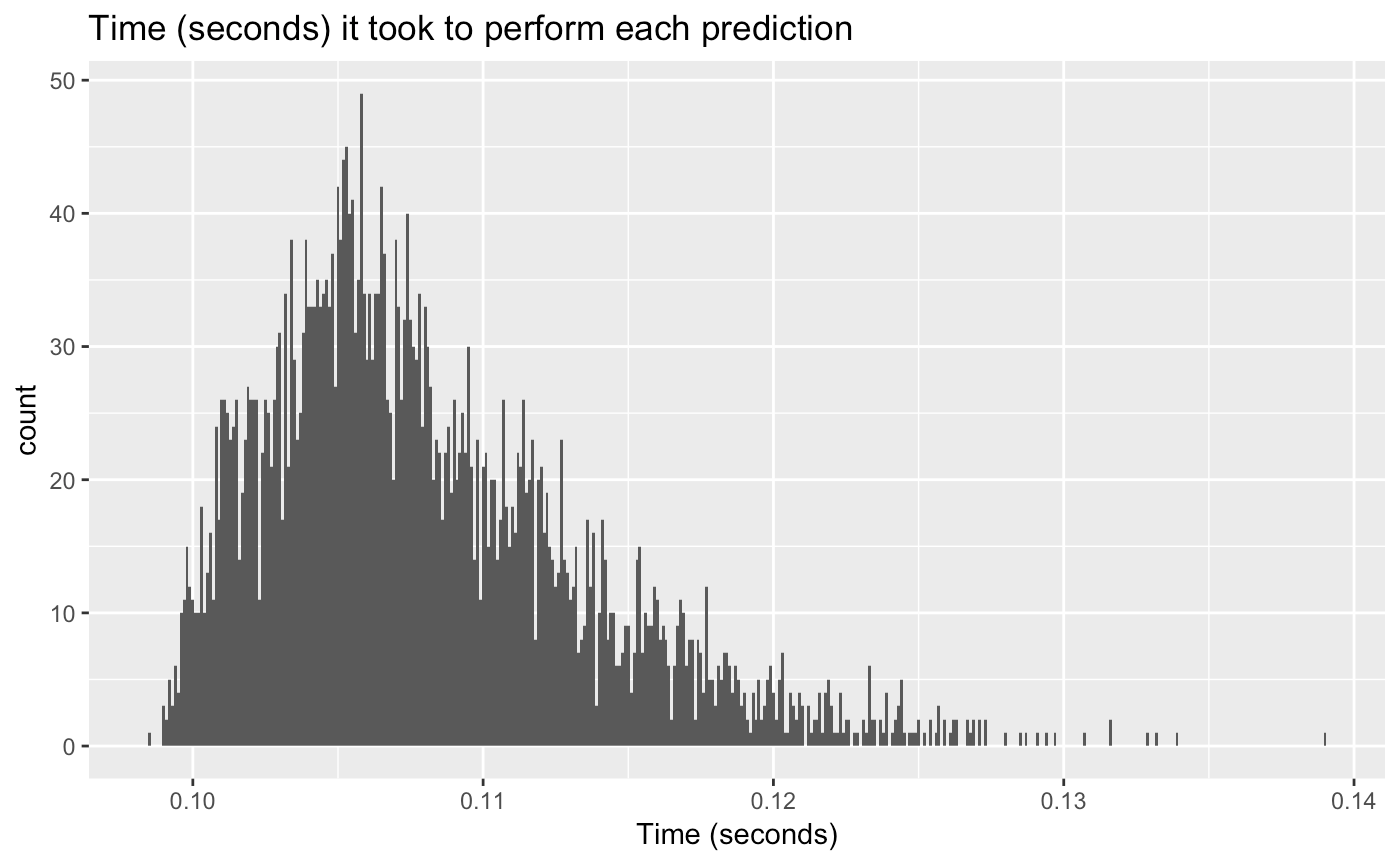
Lazy learners algorithms, such as the one used in this experiment, are typically slower than its counterpart, eager learners. This kind of systems does not generalize from the training data — hence the lazy term — until a request for a prediction arrives. Then, at the prediction stage, the algorithm must scan the complete training set to compute its result. To know the latency of my system, I test it against a test dataset of 4000 rows to gather data about the time it took to predict each recommendation. On the plot below we can see how the times (in seconds) resemble a right-skewed distribution, indicating that there are several cases in which the prediction time was far from the mean. However, since the values are themselves pretty small, a difference of a couple of milliseconds is non-noticeable.
Recap and conclusion
This article explained step-by-step how to build from scratch a neighborhood-based recommendation system written in Golang to predict League of Legends champions, and how to deploy it in Heroku. For starters, I mentioned a few words about the state of recommendations systems in video games and the vision of this project. Following this, I explained the algorithm, the data and the steps to obtain it. Then we got into the details of the system and learned about its features and the cloud deployment process. Lastly, I concluded by showing some benchmarks.
I should mention that this engine is by no means perfect nor complete and that it is a proof of concept on how we could build recommendation systems for a video game. League of Legends and the champions selection component of the game involves more complex processes such as the banning of champions (champions that can’t be used by any player), and the order in which each player selects its champion. These are processes that require a high level of expertise, something that can’t be that easily automated or learned.
In the future, I would like to add more features like an automatic update of the dataset, filtering the recommendations by game type, and even trying to add the concept of “player positions” in the algorithm.
The code, scripts, instructions about how to use the service, and everything presented in this article is available at my GitHub (juandes/lol-recommendation-system), so I’d like to invite people to contribute and experiment with the project, or the service (again, please do not abuse it).
Thanks for reading :)