How (and why) I built an over-complicated data-driven system to remind me to drink water
Data, Golang, Python, Android, Docker, gRPC, Firebase, Cloud, BigQuery. Oh my!

Water. Agua. H2O. The elixir of life. The envy of the other planets.
Yet as essential this divine liquid is to us humans, we, and by we I mean I, usually forget to consume it. At the time of writing, I’m backpacking through Asia. Amid the excitement, enjoyment, and adventures of my new life, drinking water is a thought that barely crosses my mind. And when it does, I typically disregard it telling myself, “Nah, I’ll be fine. It’s just water. I’m not thirsty anyway.” But then, the night arrives, and in the winding down of what was another successful day, the headaches and tiredness come, reminding me that I should have refilled my bottle. Obviously, I had to find a solution.
As a data practitioner, of course the solution had to involve data. But I wanted more than that — I wanted something exaggerated. My problem could have been easily solved by setting a timer or by downloading one of the many water-drinking-related apps. But no — again, I wanted more. Suddenly the problem became more a matter of how far can I take my solution than just reminding me to refresh my life a little. But a more realistic reason why I built this is because I honestly missed working with such a system. Back when I was employed, I used to deal with data, Golang, cloud, and production systems every single day. Now I don’t. So, I wanted to put together a system, where I could use all these tools (also I don’t want to become rusty, since I know I’ll have to impress the recruiters once I decide to say goodbye my outdoor adventures and replace them for an office chair).

My over-complicated platform, which I named Team Aqua after the famous Pokemon villainous team who wanted to expand the sea, destroy all human civilization and return the world to its original state (Pokemon can be very, very violent), uses the following platforms/services/components:
- A Fitbit device
- Fitbit’s API
- One Python service
- Two Golang services
- gRPC (and thus, Protobufs)
- Firebase (Messaging Service)
- An Android app
- Docker
- Google Cloud’s Container Registry
- Google Cloud’s Compute Engine
- BigQuery
- Google’s Data Studio
In this piece, I’ll describe how I built the system, how it works, and of course the source code behind it. However, for simplicity reasons and to keep this piece as short and focused as possible, I won’t explain every nook and cranny of the platform — e.g., what Gradle is and why is it used on Android. Nonetheless, at the end of the article, you’ll find a link to the system’s repo.
Now to the explanation.

Overview
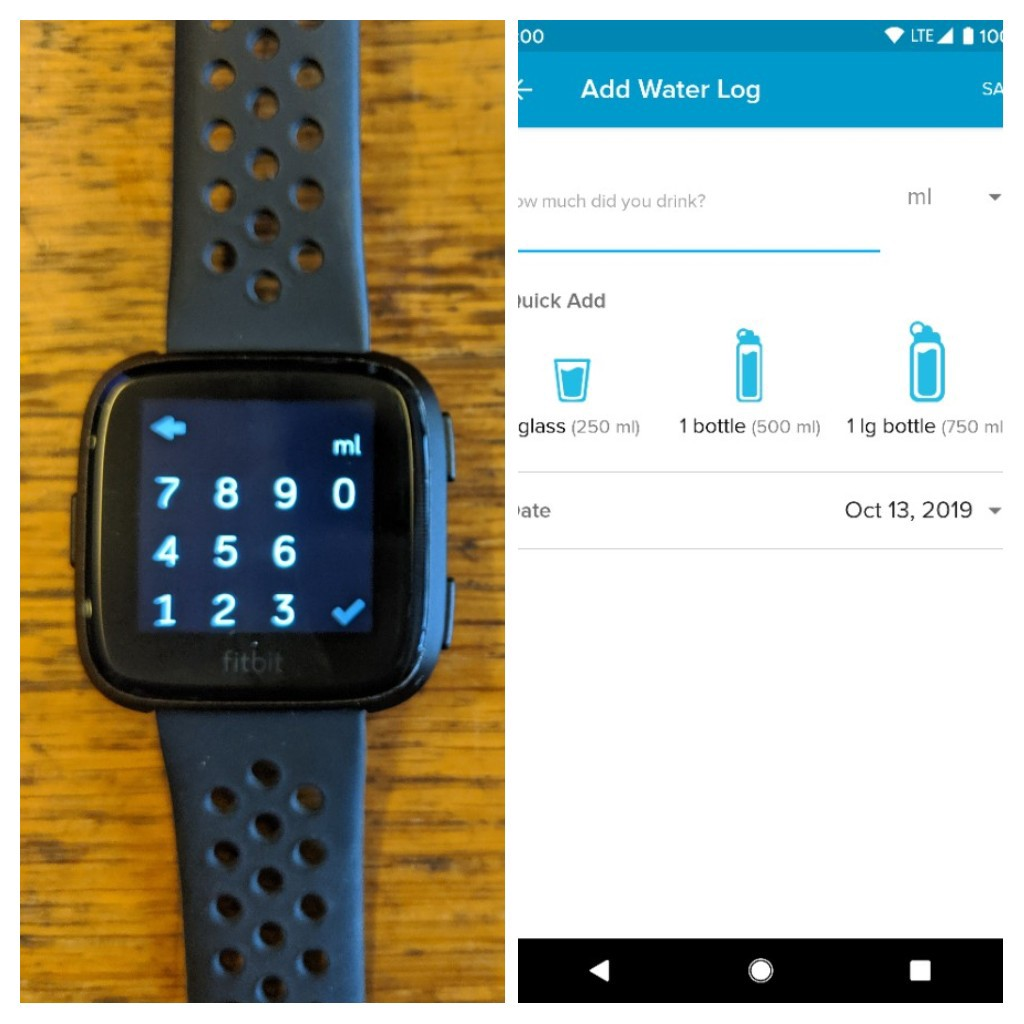
Before I start to explain each component, I want to give you a small recap showing the system’s architecture, all the moving pieces, and what they do. The beginning of this lovely tale takes place on my Fitbit watch (or app). Here, I’m going to entry each water session (let’s call it that), generating in the process the data the platform needs (that’s why I’m calling this a data-driven solution). After logging the water session, this data will be sent to Fitbit and stored there.
To retrieve this data, I have a Python service (called Water Retriever) that talks to Fitbit’s API every X minutes and gets all the water sessions I’ve logged today. Then, the Python client will communicate through gRPC, with the back-end (written in Golang), which I named Archie, after Team Aqua’s leader. Archie’s role is to keep the water sessions in memory and write them into BigQuery.
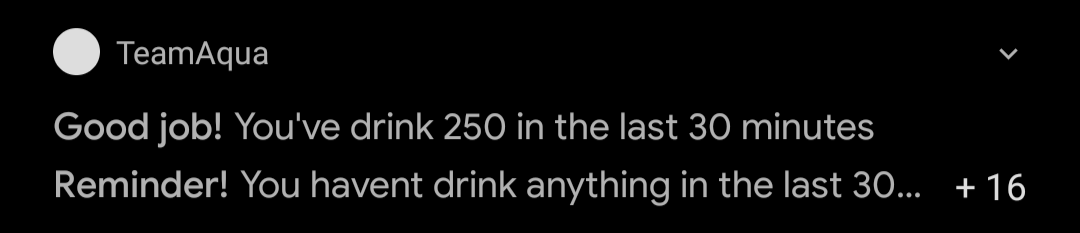
Besides Archie, there’s a second Golang component, called The Reminder. This little fella will ask Archie, every X minutes, for the amount of water I’ve consumed during that time. If I’ve consumed not a single drop of water during this time, it will send a notification to an Android app I wrote as part of the platform, reminding me that I haven’t had any water in the last X minutes. Otherwise, if I have hydrated myself, the notification will congratulate me, saying I’ve drink Y ml. of water in the last X minutes. The push notification is handled by Firebase Cloud Messaging.
The three services are contained in the same Docker image, which is hosted in Google Cloud’s Container Registry. Said image is executed on a “normal” Compute Engine machine (not a Kubernetes cluster, Cloud Run, or any of that fancy stuff). Lastly, to analyze the data, since it already resides in BigQuery, I just run a couple of queries and visualize them using Google’s Data Studio.
The following image is a chart of the complete architecture.
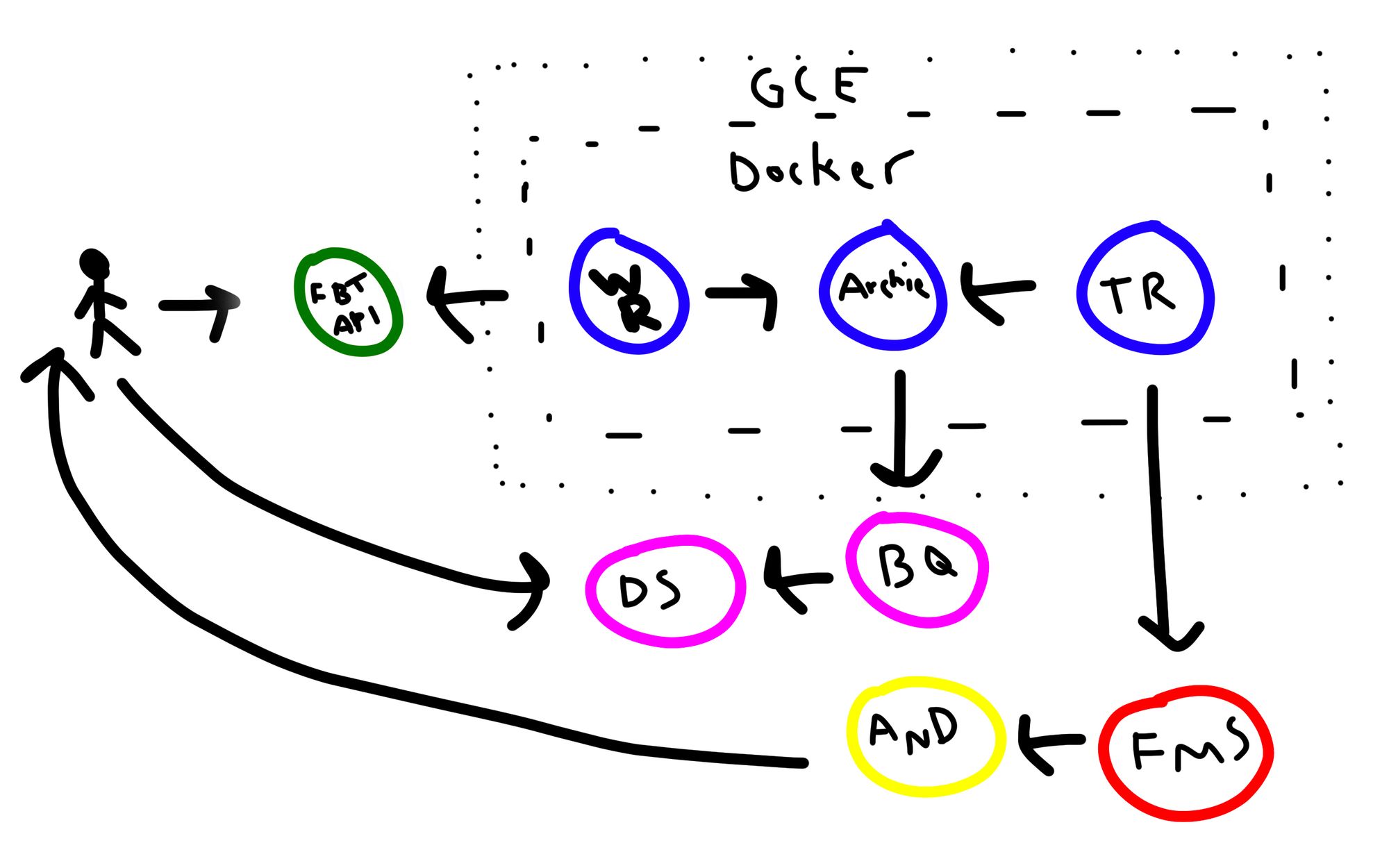
First, there’s me, logging the water data in Fitbit and sending it to their servers. Then, Water Retriever (WR) gathers this data and sends it to Archie, who keeps the data and writes a copy in BigQuery. Next to it, there’s The Reminder, who gets data from Archie and send a notification that ultimately is read by me.
In the route below Archie, there’s BigQuery, who provides data to Data Studio for me to analyze it.
Now, without further ado, let’s look at the specifics.
Fitbit Device
The system’s entry point and the place where the data is generated is my Fitbit. Here, every time I drink water, I’ll enter the amount of it. How do I really know the exact quantity? Well, I don’t! Unless I’m drinking from a bottle that has its volume written on it, I usually just estimate it.
Python Service (Water Retriever)
The first of the services I want to introduce is Water Retriever, a Python program that queries Fitbit’s API every X minutes to retrieve how much water I’ve consumed on the current day. To develop it, I used the phenomenal library, python-fitbit, to interface with the API. This is the code:
The main functionality of my program lies in one function that has barely 40 lines.
In the beginning, we initialize a variable with the current time and another one with the last “logId” (named last_log_id) or Fitbit’s water session ID consumed.
Then, we create the Fitbit client, which requires a Fitbit key, secret, access token, and refresh token. To obtain these you must create a Fitbit dev account and register an app. While creating the client, you can also specify the language (some API responses include text that may be suitable to display), and the locale (or country; the list is quite limited, though). The effects of this parameter are the language of some text fields that are included in various API responses, and the unit system. In my case, I’m using “en_DE” since I want the fields in English, and to get my units in the metric system.
Once the client has been created, the following step is to connect to the gRPC backend service (I’ll describe it in the next section). Then get into an infinite loop. At each iteration, the system calls the “Get Water Logs” endpoint to retrieve both a summary and a list of water entries for a given day (today). A typical response looks like this:
{‘summary’: {‘water’: 500}, ‘water’: [{‘amount’: 500, ‘logId’: 1234567890}]}
First I check if there are any logs at all or if the newest log from the response is the same one the system previously received in a past iteration (the log id is kept in last_log_id). If any of these conditions equals true, we do nothing and the system goes to sleep for 30 minutes. On the other hand, if the “if” is false, we create an instance of something I defined as a Splash object (trust me, I’ll explain it soon) — a class made of two fields: amount, and timestamp.
In this instance, we’ll store the amount of water consumed (in milliliters) in the newest log and the current timestamp. Then, we’ll call the gRPC method LogSplash using as a parameter the just created Splash object to send to the backend the water consumed at this time. Once this is done, we’ll update last_log_id with the logId just posted and sleep for 30 minutes.
You might have noticed a serious flaw here. What if I log more than one water session within 30 minutes? In that case, unfortunately, we’ll miss them all except for the last session, since the system is only looking at the most recent one. This is something I’ll fix in the next iteration. However, to be honest, I’m pretty sure I won’t drink more than once within this period!
That’s it for Water Retriever. Now, let’s see what happens once the backend receives the Splash.
Archie and the gRPC API
Archie, one of the system’s backend services written in Go, is responsible for keeping track (in-memory) of the water sessions, henceforth known as a Splash. But before I get there, I want to describe my project’s API service, which is based on gRPC.
To refresh your memory, I’ll quickly say that gRPC is an RPC (remote procedure call) framework. To put it simply, it is a communication protocol for executing a procedure (in this case, functions) from one system to another. What I really like about gRPC is that it’s defined using Protocol Buffers (also known as Protobuf), a “language-neutral, platform-neutral, extensible mechanism for serializing structured data.” What I mean here is that once the service and objects are defined in Protobuf, you can use one of the many code generators to convert it to one of the many languages it supports.
The whole thing is a bit tricky to grasp, but hopefully, the code will clarify things:
This is the project’s Protobuf file. In the first three lines, I’m merely setting the syntax, the package name, and importing an external time-related library I like to use. Then, I’m defining the gRPC service, named DrinkWater. The service, as you can see there, is composed of two methods: LogSplash and WaterConsumed. The former, LogSplash, which we saw before, takes as a parameter a Splash, and returns a LogSplashResponse, while the latter, WaterConsumed, takes a Since object, and returns a WaterConsumedSince (I’ll get the details soonish). But what are all these water and splashy-splashy thingies?
Right after the service, you’ll find the definition of these messages. The first of them, Splash, contains two fields: a Timestamp object (that thing I imported) and an integer (water in ml.). Then, there’s LogSplashResponse, which consists of a boolean that will be false if an error occurred during LogSplash, and a string explaining the error (if there’s one). Following this, is the Since message, which encapsulates a Timestamp. Then, lastly, is WaterConsumedSince, made of a single integer.
While these five structures define my complete service, they aren’t actual source code I could use. So, my next step was to generate Golang and Python code. In my experiment and my opinion, generating the Go code is way easier than the Python. With only one command $ go generate protoc -I=. — go_out=plugins=grpc:. endpoint.proto (executed from the directory where the Proto file is) you’ll be able to generate the code. Nonetheless, my experience with Python wasn’t the best due to some issues related to the path where the generated code resides. For those of you who are curious about how I created the Python code, this is the command I ran (from the Water Retriever’s root directory)
$ python3 -m grpc_tools.protoc -I.:${PROJ}api/v1/ \
— python_out=app/api/v1/ \
— grpc_python_out=app/api/v1/ ${PROJ}api/v1/endpoint.proto
But the story doesn’t end there. If you run Water Retriever as it is, it won’t find the generated code. So, I had to go to one of the many __init__.py files and append the current directory to the PYTHONPATH (I hated this part).
Ok! Now we have our generated code! But I won’t show that here. No! That’s boring. Instead, I’m going to present what the functions are actually doing. If you might have noticed, the Protobuf definitions are just that, definitions, or the skeleton of the functions. Inside, there’s no functionality whatsoever. That has to be described by you. The following snippet shows this.
This piece of code is my Service structure, and it implements the gRPC method we previously defined. However, besides implementing functions, my Service structure is responsible for keeping the list of Splash. Moreover, this struct also contains the BigQuery uploader, the object whose function is writing rows in BigQuery. To keep it simple, I won’t show the main function of the service, where I initialize service and the uploader. If you wish to see it, check out the file here.
The first function, NewService, simply creates the new Service object. Then, there’s LogSplash, a method of service. As we saw before, LogSplash takes a Splash (and a context I won’t explain), and returns a LogSplashResponse, and an error (this is something very particular of Golang, feel free to ignore it). The content of the function is pretty straightforward. First, it prints the Splash, then it appends it to the list, and writes to BigQuery. In the end, it’ll return a LogSplashResponse where “ok” is true. The second method of the struct is WaterConsumed, and its function is to sum all the amount of water consumed after the given timestamp. And that’s the end of Archie.
 Team Aqua’s Archie. © Nintendo (source)
Team Aqua’s Archie. © Nintendo (source)
{kind=link}
The Reminder
The second Golang service is The Reminder, and its purpose is to remind me to drink water, or to congratulate me when I do so. These reminders and congratulations will be sent as a push notification to an Android app I wrote for this sole project. The following code is the completed service. Unlike Archie, this one is entirely written in the main function (and I’m not proud of that).
The first thing the service will do is to create a connection to the gRPC backend. Following this, it creates a Firebase Messaging Service (FMS) client. As a way to know that everything was set and running correctly, I’ll send a push notification to my app, telling me that the service is up. Time for another note here. To post a message to a particular device, you need to know the phone’s Firebase token, which can be obtained directly from the app (I’ll show more later). Once that’s done, we’ll spawn a new Goroutine (think of it as a background thread) with an infinite “for” loop that will be triggered every X minutes.
At each loop iteration, we’ll calculate the current time minus X minutes. Then using this new time, the system will call the WaterConsumed gRPC method to obtain the amount of water I’ve logged since then; the call returns a Since object. If the quantity of water consumed since time t equals zero, it will send me a notification saying something like, “you haven’t drink anything.” Otherwise, the message will say, “you had drunk XXX ml of water in the last X minutes.” Additionally to this, the service is listening on a given port. Currently, this is not doing anything (besides returning “Hi!”), but I’m planning on using it to perform health checks.
Android App
The final significant component of this platform is an Android app, whose only purpose is to receive messages from FMS and forward them to me. Honestly, that’s all. In the next screenshot, you’ll see that the app is just an empty screen with a “Hello World.”
As for the code, it is also as simple as the app looks. It only contains one Activity (screen), whose purpose is printing the device’s Firebase token, which it’s needed to specify the target of the notification. Before doing this, we need to first install the Firebase SDK on the app. However, that’s another story I won’t touch. This the activity’s code.
BigQuery and Data Studio
One of Archie’s raison d ‘être is writing the generated data into BigQuery so I can go back later to it and analyze it. Now, you might be thinking: why? If there data is already in Fitbit’s servers, why am I storing it again? Well, I want to make this as complicated as possible! But the real reason is because of Data Studio, an interactive dashboard that seamlessly integrates with BigQuery, and visualizes the data after a couple of clicks.
In Data Studio, I created one dashboard that presents shows a line chart with the amount of water consumed per day, a table with the number of Splashes, and two “scorecards” that display the total water consumed, and the daily average. The following screenshot shows an example.
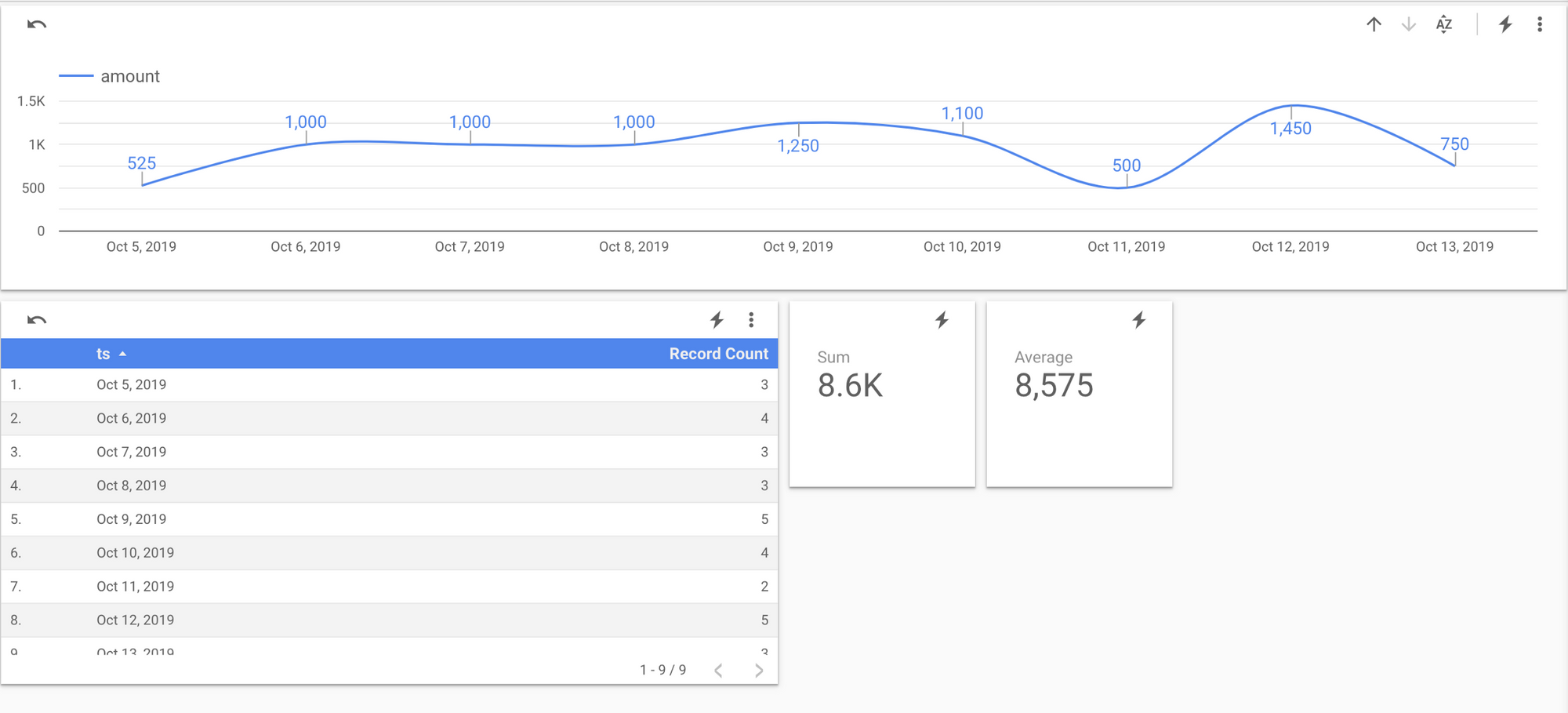
I still need to drink more water.
Deployment and Docker
The finish line is almost there. To cross it, there’s one last thing we need to it, and that’s, deploying and running the system. As expected, this wasn’t as direct as I’d like it to be. Most of the issues (they weren’t actual issues, just small hiccups) I experienced here started due to the microservices architectural design of the system, and because I wanted to keep everything in the same Docker image. On top of this, since I’m using several secrets and keys, I had to think about their management. Let’s take a look at the whole (and short) process.
The first step is creating a Docker image; its base is the official Golang one. Then, as for the first instruction, we’re going to copy the whole project (yes, everything!) to the image. Following this, we’ll run a few tests (very important!) and build the Go binaries inside the container. By doing so, we’ll avoid possible cross-compilation problems. After that, we need to install Python 3 (it’s 2019, people), some tools, and the libraries Water Retriever needs. In the last step, we’ll execute run(.)sh script that starts the services. The two scripts below are both the Dockerfile and run.sh.
The run.sh script will first execute both Go service in the background using GNU Screen (if anyone knows a better way, please let me know). Then, in the foreground, we’ll start Water Retriever. Keep in mind the different arguments (Google Cloud project, Firebase token, among others) the components need; these will be taken from environmental variables. Moreover, Water Retriever also requires the Fitbit keys, which also come from env vars that you, yes, you have to declare when running the Docker image. The next line is an example of the command I’m using.
docker run -d -e FITBIT_KEY=ABCDEF \
-e FITBIT_SECRET=abcdef1234567 \
-e ACCESS_TOKEN=12345678 \
-e REFRESH_TOKEN=12345678 \
-e GOOGLE_APPLICATION_CREDENTIALS=path/to/credentials.json \
-e GCP_PROJECT=xxx \
-e BQ_DATASET=xxx \
-e BQ_TABLE=xxx \
-e FB_TOKEN=xxx \
gcr.io/xxx/xxx:tag
Speaking of running Docker, I’d like to mention that instead of pushing the image in a public repo (sorry, it contains way too many secrets), I pushed it in Google Container Registry. In hindsight, that was the right decision because, from the Registry’s GUI, you can quickly spawn a new Compute Engine instance with the image already loaded in it. By default, the machine will execute the image, but in my case, it crashes because it lacks the credentials, keys, and so on. So, you’ll have to SSH and manually run it.
Wow, I think that’s all!
Recap and conclusion
In the last 3000 words, I introduced a platform whose goal is to remind me to drink water. Again, I’m aware that I could have used one of my many apps available for precisely this purpose. However, I wanted to build my own, and moreover, see how far I could take it. The project won’t end here (ok, maybe it will). There’s a list of features such as the health check I mentioned, a custom dashboard, metrics, alerts I’d like to implement. But in the meanwhile, I’ll enjoy a nice glass of water (and log it).
Thanks for reading.
The code is available at https://github.com/juandes/team-aqua
This article is part of my Wander Data series, in which I’m telling and reliving my travel stories with data. To see more of the project, visit wanderdata.com.
![]() Wander Data
Wander Data