What did Puerto Rico say after its governor resigned? A Twitter data analysis

Interpreting tweets containing the hashtag #RickyRenunció using spaCy, Google Cloud, and NLP.
The island of Puerto Rico and its people are currently making history. On July 13, the Puerto Rico’s Center for Investigative Journalism published a document consisting of 889 pages of Telegram messages interchanged between the governor, Ricardo Roselló, and inner members of his staff. Its content included messages of misogynistic content, homophobia, sexism, vulgar language, and even jokes towards the victims of Hurricane María.
The people of PR didn’t approve such conduct from its governor and didn’t want to be represented by him. Thus, as a result of the leak, and a corruption case that erupted days before it, on July 15, over 500,000 Puerto Ricans took over the streets of Old San Juan and held protests for twelve consecutive days, including a national strike on July 23 in which over 750,000 people assisted.

But the strikes didn’t end on the streets of San Juan. Thousands of Puerto Ricans who don’t reside in the island, held manifestations all over the world to make themselves heard and to show sympathy for those fighting in Old San Juan. Moreover, the manifestations also lived in social networks. There, the people made themselves heard through comments, discussions, and memes.
After twelve days of protests, on July 25, Ricardo Roselló resigned, effective August 2. And in the same way that Puerto Rico and the world raised their online voices, once again, they made themselves heard and celebrated their victory through social networks.
To have a better idea of how the Puerto Ricans took their celebrations online, I collected a total of 20058 tweets containing the hashtag #RickyRenunció (Spanish for “Ricky [Ricardo’s nickname] resigned”) as they were generated, to analyze them.

In this article, I’ll present the results I found during my investigation. In it, I used Natural Language Processing (NLP), artificial intelligence, the programming language Python, the library spaCy, and Google Cloud’s Natural Language API to interpret the tweets’ content and have a better understanding of what Puerto Rico and the world said in the aftermath of Rosello’s resignation. Armed with these tools, I analyzed the complete tweets’ corpus to investigate the following concepts:
- The top nouns, verbs, adjectives, and adverbs present in the tweets.
- The sentiment or writer’s attitude present in the tweets.
Brief side note before I begin: Even though this article is about using artificial intelligence and programming to research the topics mentioned above, I’m aiming to reach the general audience with the content I’m about to present. Thus, I’ll use a user-friendly vocabulary and will keep the technical jargon at a minimum. Nonetheless, there will be some small pieces of code for those who want to replicate the experiment; however, if you aren’t interested, feel free to ignore them. Also, when analyzing the data, I realized that I was reading the “short form” of the tweets (a huge mistake), instead of the full text, so every tweet is truncated to 150 characters, and since I was gathering the data in real-time, I couldn’t revert the process.

The data and preparation step
The tweet’s corpus consists of 20058 tweets, collected during July 25 and 26 using the Python package, Tweepy. The dataset contains all kind of tweets, for example, tweets with images links, tweets with mentions, and retweets. As a result, I had clean and pre-process the data to make it suitable for the different use cases I wanted to investigate.
To discover the top nouns, verbs, adverbs, and adjectives, collectively known as part-of-speech (POS), I removed the hashtags, mentions, retweet mentions, e.g., “RT @account_name,” and the https addresses from tweets that contained images. Moreover, as part of spaCy’s data processing step, the algorithm will ignore the stop words, which are the commonly used words, such as “tu (Spanish for you)” and “yo (Spanish for I).” Also, I’m only using the lemma, that’s it, the canonical form, of each word. For instance, the verbs “hablamos,” “habló,” and “hablando” are forms of the same lexeme, and its lemma is “hablar (Spanish for talk).”
The following piece of code shows the cleaning process.
import re
with open('data/tweets_no_location.txt', 'r') as file:
text = file.read()
# remove RT mentions
text = re.sub('RT @[\w_]+:', '', text)
text = re.sub(r'https?:\/\/.*[\r\n]*', '', text)
with open('data/cleaned_tweets.txt', 'w') as file:
file.write(text)
text = re.sub('@[A-Za-z0-9]+', '', text)
with open('data/cleaned_tweets_no_mentions.txt', 'w') as file:
file.write(text)
text = re.sub('#[A-Za-z0-9]+', '', text)
with open('data/cleaned_tweets_no_mentions_hashtags.txt', 'w') as file:
file.write(text)
```
 Old San Juan.
Old San Juan.
The top nouns, verbs, adjectives, and adverbs present in the tweets
One of spaCy’s most powerful features is the part-of-speech tagging, which assigns a predicted label, such as noun and verb, to each document’s term, allowing us to put some context and meaning to the acquired tweets. To perform this, I used what’s known as a language model, which in layman’s terms is an artificial intelligence entity that has learned a language’s characteristics after being exposed to thousands of words from that language.
The news of the events that happened in Puerto Rico became international. Hence, the people commenting about it weren’t just Puerto Ricans nor Spanish speakers. As a result, many of the tweets collected are in English, so I had to use two languages models — a Spanish and English one — to better assess the content.
Important note: the Spanish model is trained with words taken from the Spanish Wikipedia and news articles, and unfortunately, its performance suffers when it’s used in other genres, such as a social media text. Nonetheless, I manually fixed some of the inconsistencies by removing the emojis, and words in a language other than the one specified from the results. So I’m confident that the overall outcome of the analysis wasn’t affected due to this reason. In the repository appending this article, you can find the completed and untouched output. With that note out of the way, let’s proceed with the analysis.
In this section, I’ll illustrate, through eight visualizations (four in Spanish and four in English), the top ten nouns, verbs, adjectives, and adverbs that Twitter was using while talking about the resignation of the governor Ricardo Roselló.
Here is a code snippet showing how I obtained the POS tags using spaCy (remember: you can ignore it).
import spacy
import re
import itertools
import numpy as np
import pandas as pd
from spacy import displacy
def top_pos(doc, pos, n, model_language):
"""Finds the top n spaCy pos
Parameters:
doc: spaCy's doc
pos: pos we are interesting in finding; one of "VERB", "NOUN", "ADJ" or "ADV"
n: how many pos
"""
pos_count = {}
for token in doc:
# ignore stop words
if token.is_stop:
continue
if token.pos_ == pos:
if token.lemma_ in pos_count:
pos_count[token.lemma_] += 1
else:
pos_count[token.lemma_] = 1
# sort by values, but before get only those keys where value > 1;
# I want lemmas that appear more than one
# lastly, get the first n results
result = sorted({k: v for (k, v) in pos_count.items() if v > 1}.items(),
key=lambda kv: kv[1], reverse=True)[:n]
df = pd.DataFrame(result, columns=[pos, 'value'])
df.to_csv('data/{}_{}.csv'.format(pos, model_language), header=True, index=False)
print("top {} {} {}".format(n, pos, result))
def start_analysis(model_name, language):
nlp = spacy.load(model_name)
with open('data/cleaned_tweets_no_mentions_hashtags.txt', 'r') as file:
text = file.read()
nlp.max_length = len(text)
doc = nlp(text)
for i in ['VERB', 'NOUN', 'ADJ', 'ADV']:
top_pos(doc, i, 30, language)
if __name__ == "__main__":
start_analysis('es_core_news_md', 'Spanish')
start_analysis('en_core_web_lg', 'English')
Verbs
The first POS I want to introduce are verbs, words that convey action. Firstly, I’ll show the top Spanish verbs, followed by the English ones.
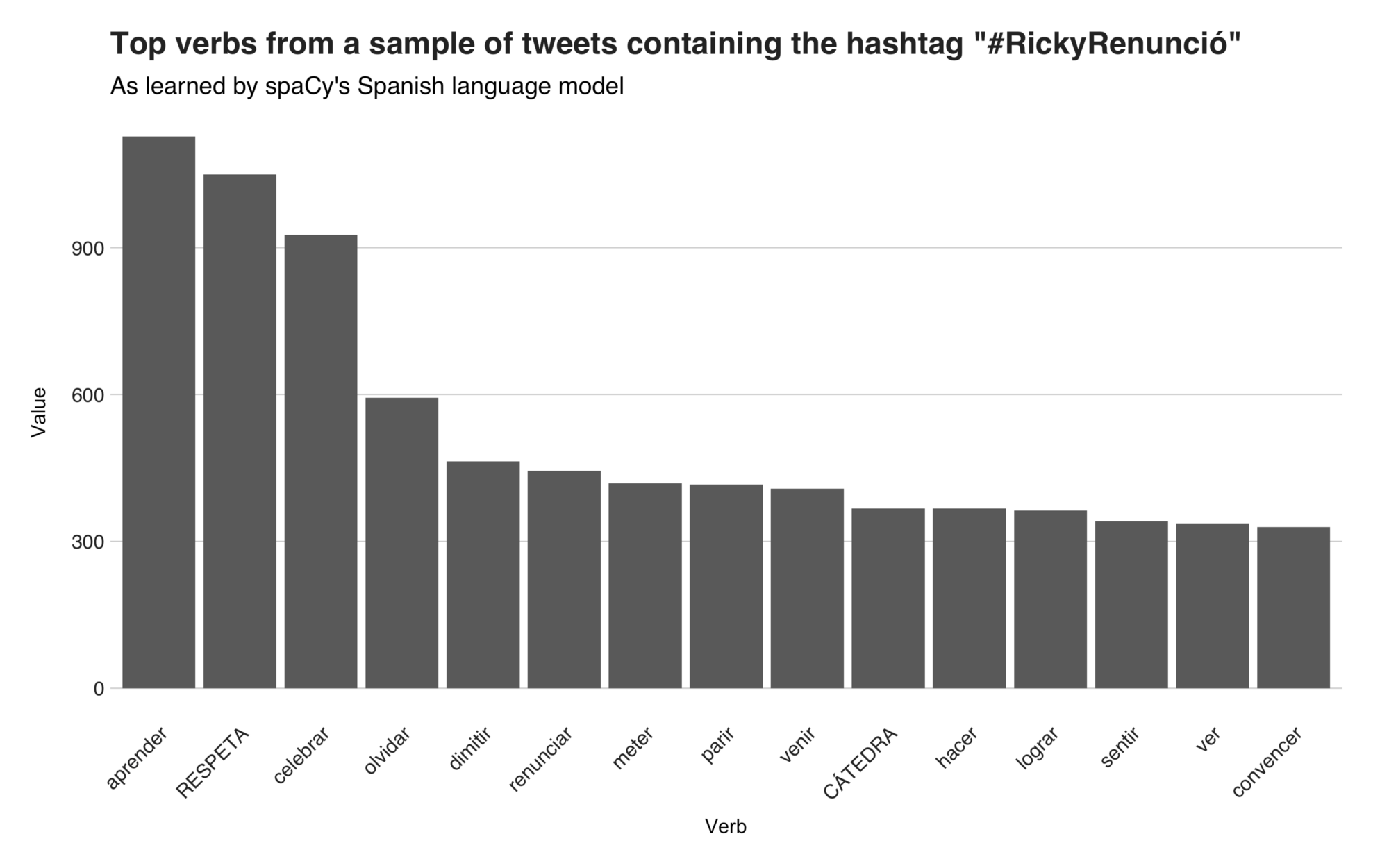
On top position, we have the word “aprender,” which is Spanish for “learn.” This term appears mostly in a retweeted tweet that states that in the twelve days of protests, Puerto Rico has given a lesson to the world that everybody should learn. Likewise, the term shows up in tweets from people saying that their countries, e.g., Mexico, and Brazil, should learn from what happened in Puerto Rico. On the second position, there’s the capitalized word “RESPETA,” which means “respect,” and it comes from tweets saying that Puerto Rico and Latin America in general, deserve to be respected. (I left the capitalized words capitalized because I believe they have another sort of meaning when compared to the non-capitalized version). The third verb is the word “celebrar” (“celebrate”), which appears in a retweeted tweet aimed to Luis Fonsi (Puerto Rican singer, Despacito guy), telling him that he doesn’t deserve to celebrate because he didn’t show up or acknowledge the protests nor the movement. Then, there’s the word “dimitir” (resign), “renunciar” (also resign), “meter” (introduce), “parir” (give birth), “venir” (come), “CÁTEDRA” (slang for lesson), “hacer” (to do), “lograr” (achieve), “sentir” (feel), “ver” (see), and “convencer” (convince). Now, let’s see the English counterpart.
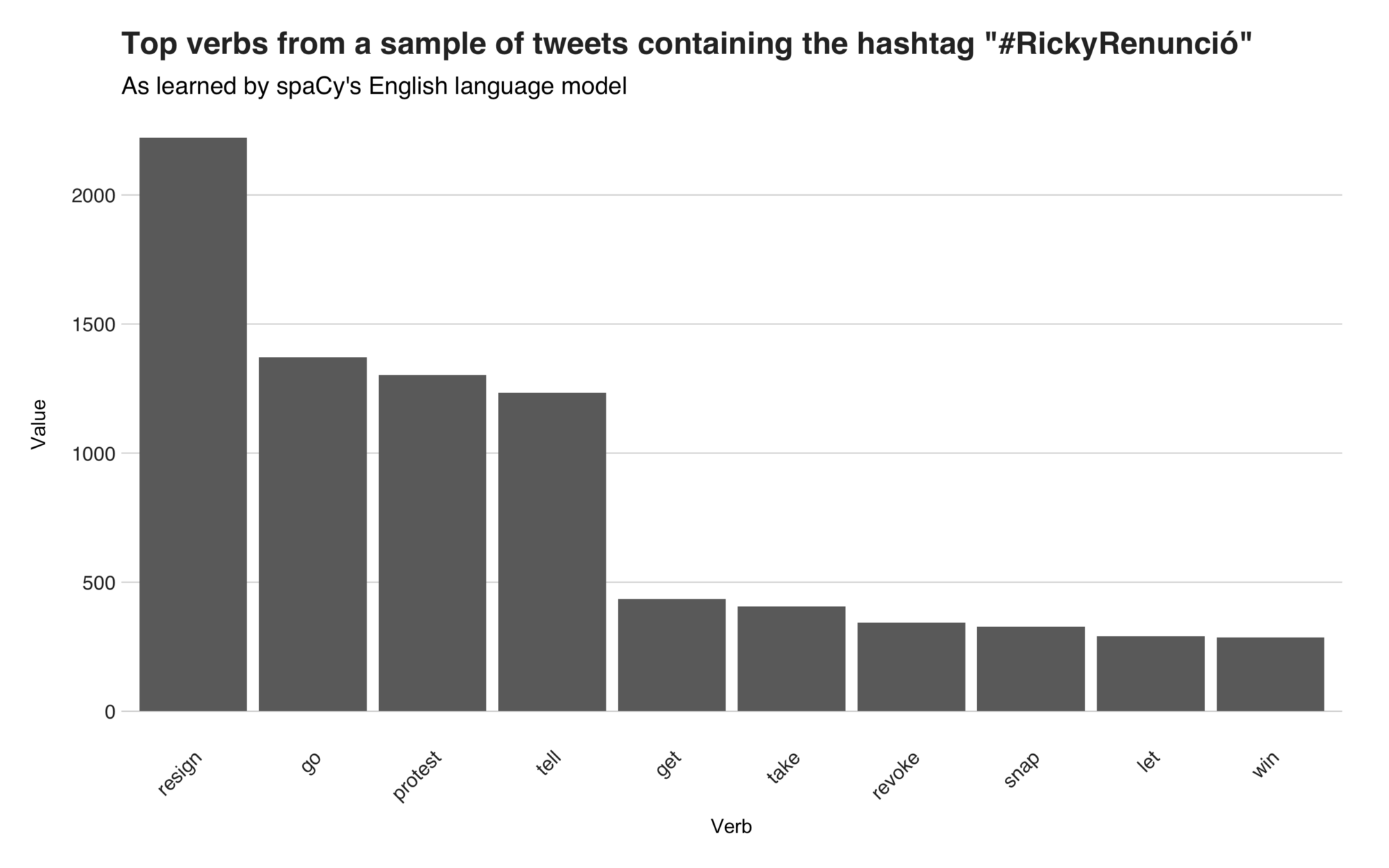
On the first position, there’s the word “resign,” and it shows up in tweets from people talking about the resignation, and about how Trump could resign if the United States would do the same. Then there’s “go,” alluding to go out and vote, or go out and protest. Following it, we have “protest,” referring to the protest itself. The rest of the verbs are: “tell,” “get,” “take,” “revoke,” “snap,” “let,” and “win.”
Now that we know the verbs, I’ll proceed to show the adverbs, the words that modify them.
Adverbs
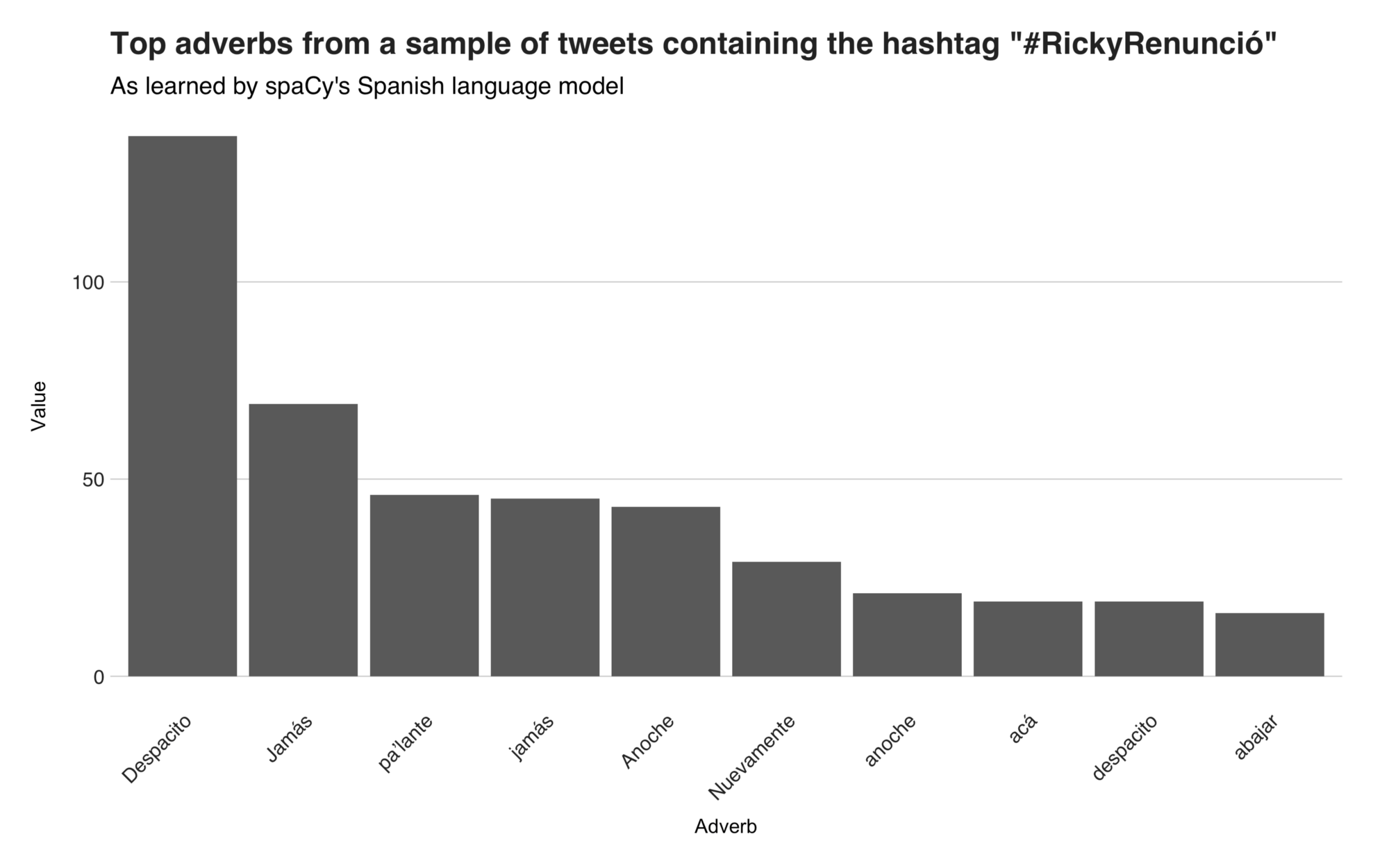
The first adverb from the list is “Despacito” (slowly), which is also the title of the 2017 hit song by Luis Fonsi and Daddy Yankee. The Twitter users are utilizing this term to tell Luis Fonsi that he should slowly back off or get out, tweets that are related to the one I presented above. Right after “Despacito,” is the word “Jámas” (never), and it emerges mostly from tweets with the phrase “un pueblo unido jamás será vencido,” which means something like “united we stand.” Then, there’s another Puerto Rican slang, “pa’lante,” which means “onward, forward,” and this one comes from a tweet by the singer Miguel Bosé, in which he’s congratulating the people. The rest of the top adverbs are “Anoche” (last night), “Nuevamente” (once again), “acá” (here), and “[sic] abajar,” which might be a typo from “a bajar” (going down).
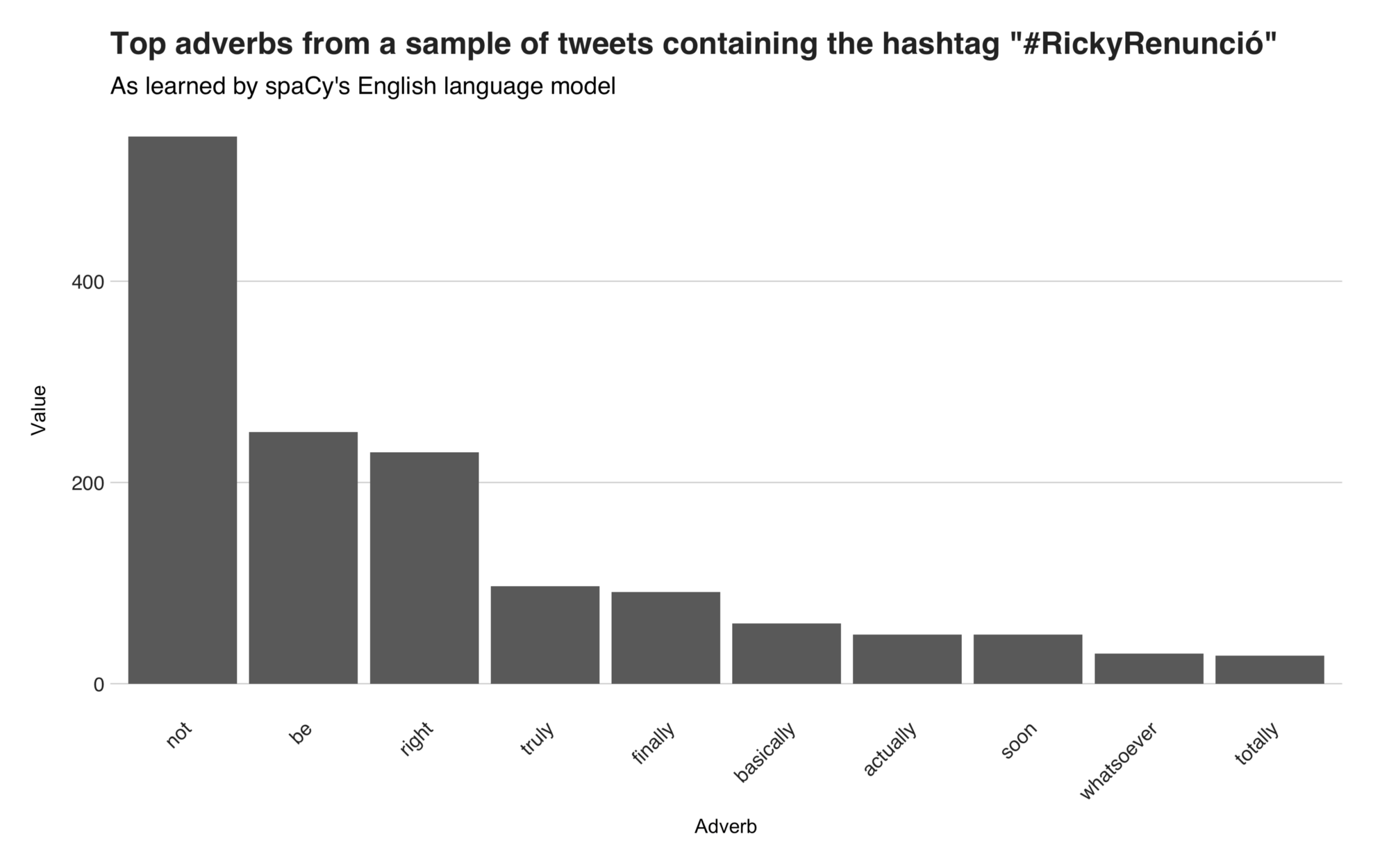
The top English adverb, “not” is all over the place and it appears in many different tweets, such as tweets of people thanking artists for not leaving them alone, tweets about people not giving up, and in tweets stating to notturn the protests against Wanda Vazquez (the appointed successor), into a misogynic one. The other adverbs from the list are “be,” “right,” “truly,” “finally,” “basically,” “soon,” “whatsoever,” and “totally.”
Nouns
Besides the verbs, the nouns are a fundamental part of a sentence. These essential words exist for the sole use of naming things; that’s it, places, persons, ideas, feelings. In this section, I’ll address the top nouns from the tweets. Then, I’ll list the top adjectives, words that describe or modify the nouns.
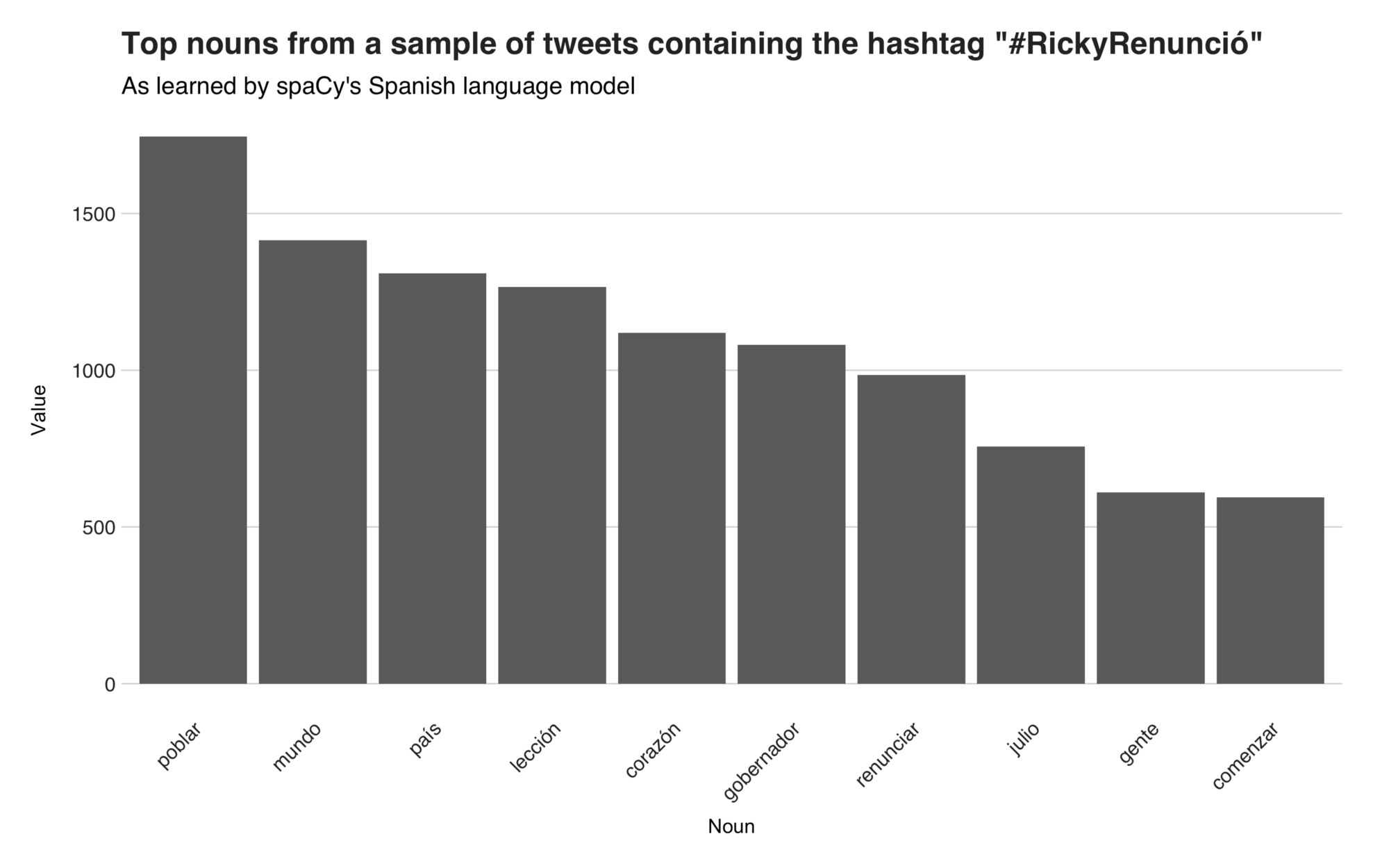
The first word from the list, “poblar” (populate) is a mistake from the language model. Firstly, this word is not a noun, but a verb, and second, it doesn’t show up in the corpus. I believe that this happened because the model misunderstood some words (maybe some English words), normalized them to “poblar” and tagged them as nouns. On spot number two, we have the word “mundo” (world), and you can find it in many tweets stating that Puerto Rico just gave a lesson to the world on how a country can achieve such achievement. Then, there’s the word “país” (country), which originates in messages about people proud of their country, messages pointing out those who fought for the country and others saying that Puerto Rico won’t ever be the same country again. The rest of the nouns include “lección” (lesson), “corazón” (heart), “gobernador” (governor), “renunciar” (resign), “julio” (July), “gente” (people), and “comenzar” (begin).
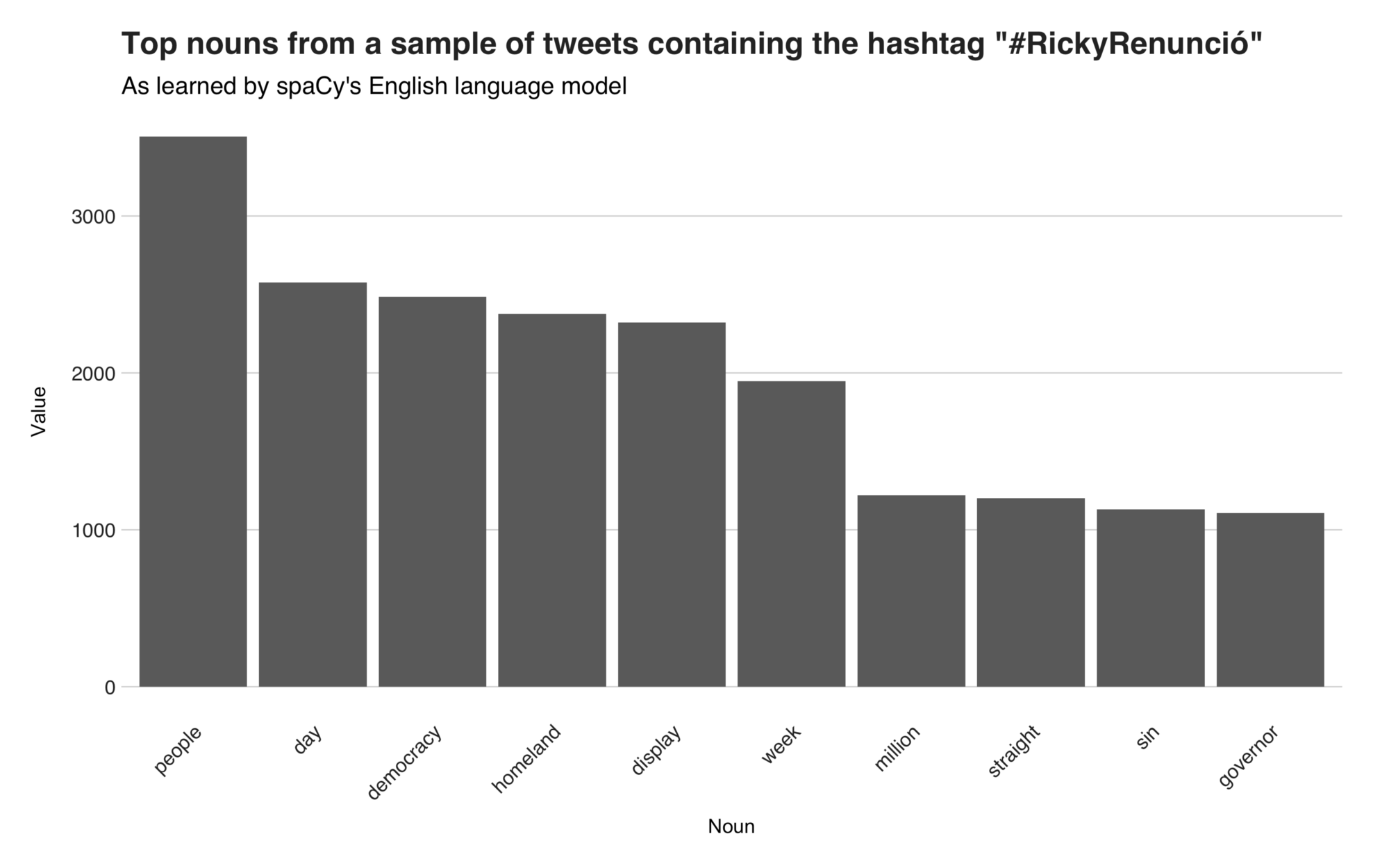
The top English noun is the word “people,” and you’ll find it in tweets that mention the people of Puerto Rico. Consequently, there’s the term “day,” present in messages telling how Puerto Ricans turned up day after day to the manifestations and messages from people saying what a great day that was. Then, the top third term is “democracy,” and it comes from another retweeted content in which a user says that Puerto Rico “has put democracy on display for 11 days straight.” The rest of the nouns are “homeland,” “display,” “week,” “million,” “straight,” “sin” (this one is a language model error raised due to the Spanish word “sin” [without]), and “governor.”
To know how these nouns were modified, I also studied the top adjectives. These next two plots show them.
Adjectives
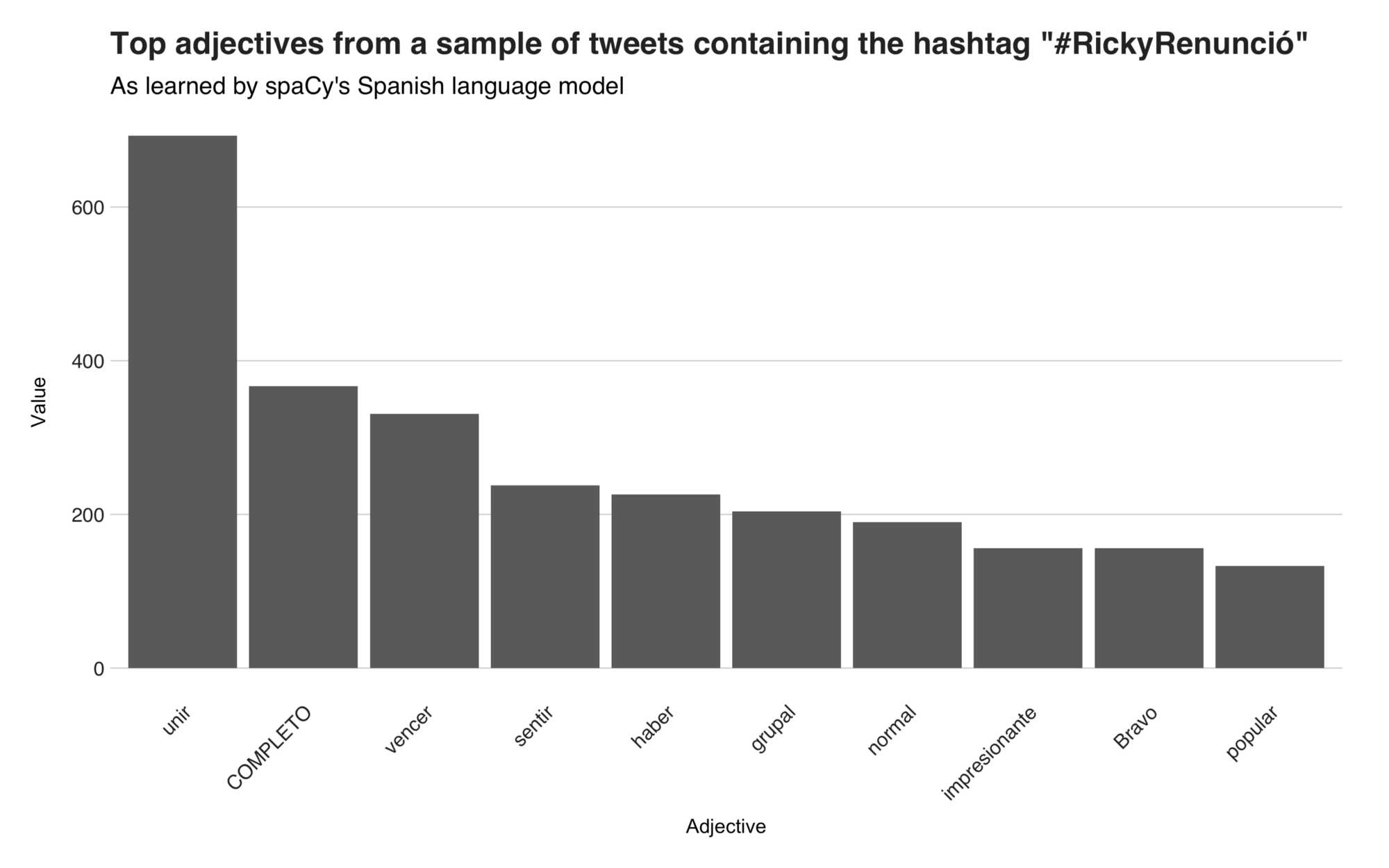
According to spaCy, the most common Spanish adjective from the corpus is the word “unir” (to unite), and while this term barely appears in the corpus, its canonical form, the word “unido” (united), does arise many times. You can find the word in those tweets that mention or talk about a unitedcountry or united people. The term that follows it is “COMPLETE” (complete), which comes from the previously discussed tweet that contains the word “mundo.” Then, there’s the verb “vencer”, which turn up on the tops because of the many instances of the adjective “vencido” (defeated), word that you’ll find in a Luis Fonsi tweet declaring that the island wasn’t defeated; this tweet was the reason why many Puertorricans backlashed against him and attacked him in the tweets discussed in the past sections. The subsequent two terms “sentir” (to feel), “haber” (to have), are possible mistakes because they aren’t adjectives, and I couldn’t find many words relating to them in the corpus. The remaining five are “grupal” (in-group), “normal,” “impresionante” (impressive), “Bravo” (brave) and, “popular.”
Lastly, I’ll introduce the English adjectives.
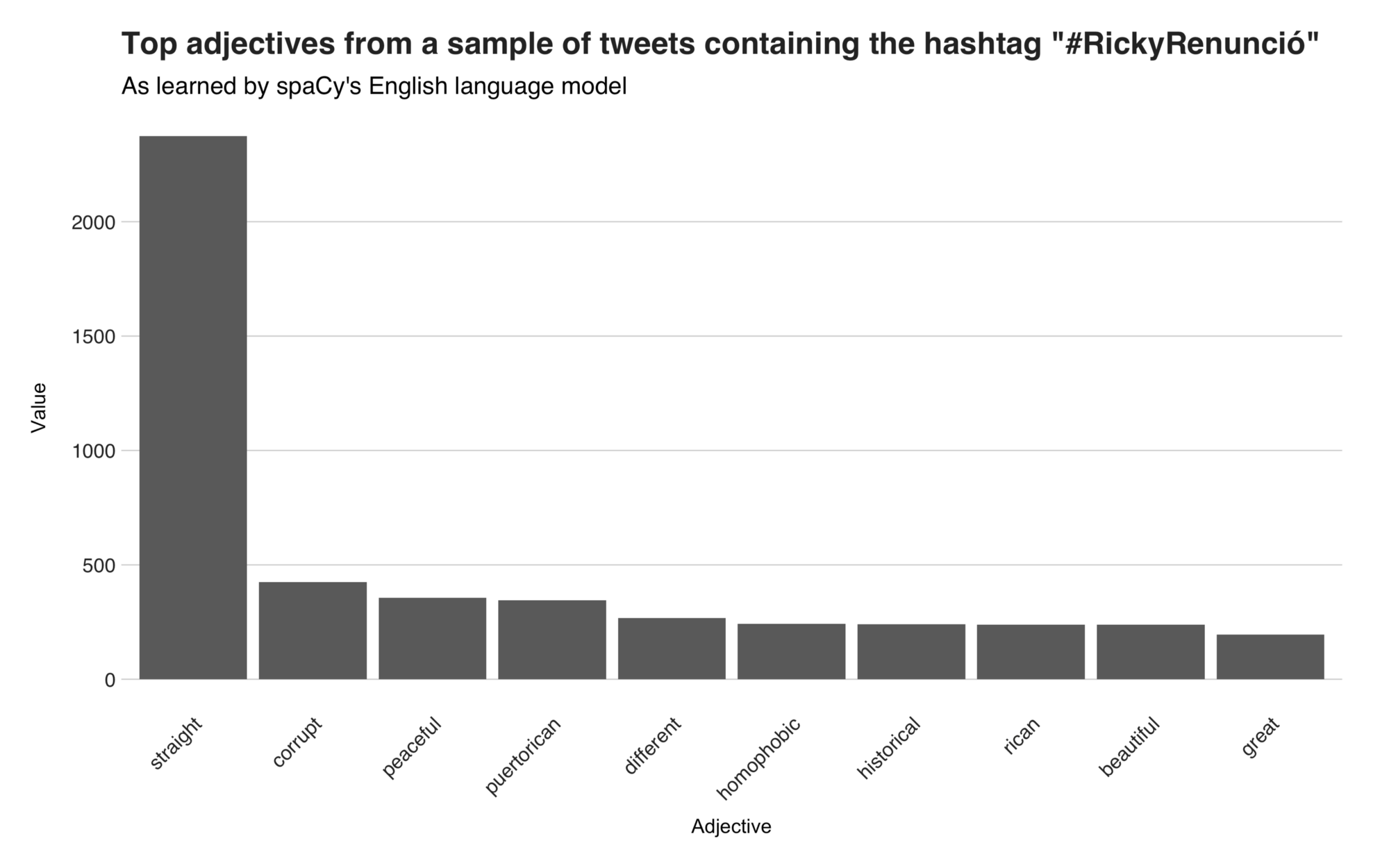
The adjective “straight” — which is part of the “democracy” tweet I previously quoted in the nouns section — lead the list by a considerable margin. Then, there are “corrupt,” and “homophobic” (6th position), two terms that mostly show up together, and are used to describe the governor and his governance. On the third spot, you can see the word “peaceful,” often used to define the peaceful nature of the protests. The remaining adjectives are “puertorrican,” “different,” “historical,” “rican” (probably from Puerto Rican), “beautiful,” and “great.”
Discussion and interpretation
The overall feeling and takeaway I got from the terms discussed, is that pride, nationality, unity, and hope for what’s to come permeated throughout the Puerto Ricans. With Spanish words such as “country,” “onward,” “lesson,” “beginning” and, “victory” the people of Puerto Rico told the world how tired they are of the abuse and treatment that has persisted in the island. On the contrary, the tweets also revealed the anger, fury, and disappointment towards the governor, politicians, and even artists.
This positive and hopeful attitude displayed by Puerto Rico transcended the borders of the island and spread out through other Latin American countries, and we saw it on tweets in which people from these places were showing their support and even a desire of starting similar manifestations in their lands.
Regarding the English tweets, I’d say they were more focused on news of the events, as well as the support and sympathy shown by those who live in the United States. Moreover, upon closer examination, I also discovered that many of the tweets contained messages directed at the United States, and its president, Donald Trump. These tweets expressed a feeling of doubt, uncertainty, and even hope regarding what could happen if the people of the US went out to take the streets as the Puertorricans did.
Sentiment analysis
The POS terms introduced in the previous section gave us an idea of what the textual meaning of the tweets was. However, due to the corpus size, it’s relatively hard to perceive a definite impression of the exact main idea behind the tweets. Despite this, there’s a way to summarize and quantify with one single number a feature of the tweets: the writer’s attitude. And the technique used to identify, extract and quantify it is named sentiment analysis, an artificial intelligence method.
To summarize the tweets’ text under one number, I ran every unique one (not duplicated) through a sentiment analysis engine to quantify the “positiveness” or “negativity” of its content. The sentiment model I used is the one provided by Google Cloud’s Natural Language API, and I chose it because of how it splits the corpus into sentences to calculate the sentiment of each.
The following code shows how I calculated the sentiments.
import pandas as pd
from google.cloud import language
from google.cloud.language import enums
from google.cloud.language import types
client = language.LanguageServiceClient()
# in my case, the corpus is stored in Cloud Storage
document = types.Document(
gcs_content_uri='gs://gcp-bucket/file.txt',
type=enums.Document.Type.PLAIN_TEXT)
annotations = client.analyze_sentiment(document=document,
encoding_type='UTF32', timeout=600)
sentences = []
for s in annotations.sentences:
sentences.append((s.text.content, s.sentiment.score, s.sentiment.magnitude))
df = pd.DataFrame(sentences, columns=['sentence', 'score', 'magnitude'])
df.to_csv('data/sentences_sentiment.csv')
In total, Google delivered the sentiment of 4880 sentences it detected. Each of the sentiment output consists of two values: the “score” and the “magnitude.” The former is a value between -1 and 1, where -1 indicates a negative emotion, and 1 means a positive feeling, while magnitude, which I won’t use here, specify “how much emotional content is present within the document.”.
The graph below shows the sentiment values.
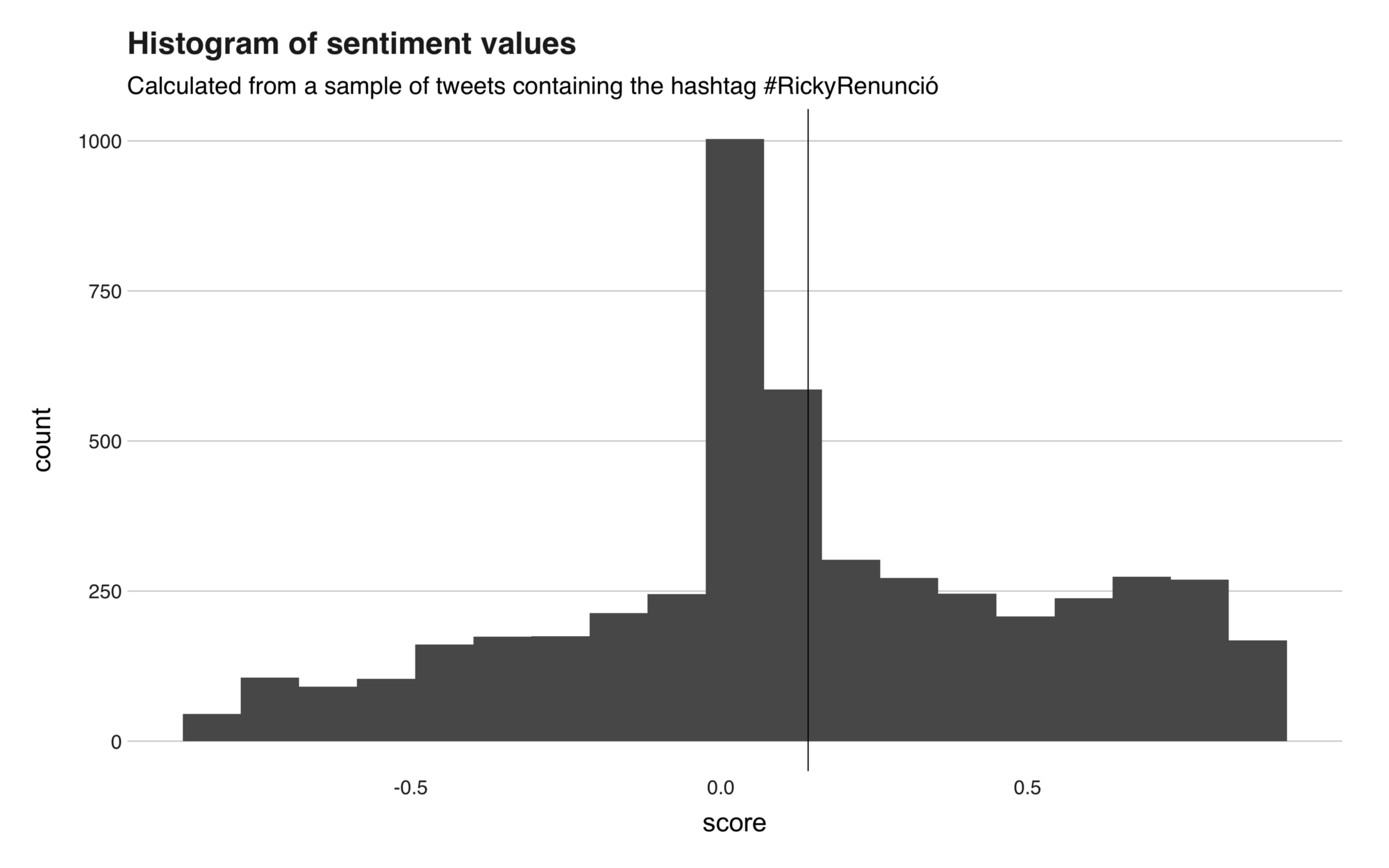
This kind of visualization is known as a histogram, and it serves to show the distribution of numerical data, which in this case are the sentiment values. At first glance, the image is telling us that most of the sentiments are somehow neutral. And that’s correct; the average sentiment value is 0.12(slightly positive). However, to tell the complete story, we need to consider the standard deviation, which is 0.42. This rather significant standard deviation indicates that the sentiment values are very spread out or dissimilar, implying that there’s all kind of tweets in the corpus.
Let’s see some examples, first, I’ll show some tweets that evoke positive emotions, and then others that suggest negative feelings.
Positives:
- “Great news!”
- “Historic!”
- “This is extremely motivating.”
- “Orgullosa de ser BORICUA ❤️🇵🇷” (proud of being Boricua [another word for Puertorrican])
- “A ver si algo de esto le aprendemos 100% Guao.” (let’s see if we learn something from this 100% wow.)
- “Me alegra que hayamos servido de inspiración para otros países.” (it makes me happy to know we have served as an inspiration to other countries).
Negatives:
- “Corruption, mendacity, abhorrent behavior…”
- “Governor Rosselló’s corruption and his hateful words added insult to injury.”
- “The people are tired of being bullied…”
- “Fuck the Puerto Rican GOVT for thinking they could keep their dirty rags behind closed doo…”
- “No te vuelvo a comprar una canción más.” (I won’t ever buy another of your songs)
- “RT @[name removed]: Que tipo mierda.” (What a shitty person)
Recap and conclusion
After weeks of protests against him and his government, the governor of Puerto Rico resigned. To celebrate this significant and historical moment, the people of Puerto Rico and the world, went to Twitter to state their opinion, share the outcome and to celebrate. As a result, I collected a corpus of tweets containing the hashtag #RickyRenunció, to conduct an experiment whose goal is to interpret and summarize what the Twitter users were saying.
In the first part of my investigation, I used the NLP library spaCy to discover the top nouns, verbs, adjectives, and adverbs, as well as the overall idea the users wanted to convey through the tweets. Upon analyzing the findings, I concluded that most of the tweets talked about the pride of being Puerto Rican, unity, and hope while displaying a sense of accomplishment and happiness. Moreover, there were many tweets by non-Puerto-Ricans expressing their sympathy and desire to emulate in their respective countries the events that just happened on the island.
Then, in the second part, I studied the sentiment of the tweets and found out that the general sentiment or attitude within the comments was slightly positive (mean value of 0.12). Notwithstanding, the standard deviation was quite high (0.42), implying that the tweets displayed a whole range of emotions and feelings.
The complete clean tweets corpus and source code is available in the following repository: https://github.com/juandes/pr-resignation-tweets. For privacy reasons, I removed every mention from the tweets.
Thanks for reading.