Object Detection in the City
Taking my Android model on a tour through the city of Siem Reap.


What’s better than a machine learning model? A deployed one. A model that’s actively producing something. The opposite of it is what I like to call “PowerPoint AI,” models that only live inside a presentation made of 57 slides. This kind of black boxes, as impressive and shiny as they sound, haven’t had the chance to experience what’s out there in the wild. They haven’t tasted good, and real data; they go straight from the text editor, to the repository. Poor them :(. Since I believe that a free model, is a happy one, I decided to load of them on my phone and take it for a walk in the historic and breathtaking city of Siem Reap, Cambodia. In this article, I'll summarize my findings, explain the overall results, and of course, present a video and several gifs from my city tour. But before we get there, I’ll quickly go through the particulars of the system.
The model in question is a pre-trained object detector — a system that identifies and localize multiple objects in an image– originally trained using TensorFlow Object Detection API, and it runs on an Android app whose code I took (and modified a bit) from the official TensorFlow’s examples repository. To be more specific, I’m using an SSD MobileNet V1 model trained on the COCO dataset…wait, what? What does this even mean? Allow me to explain. SSD, which stands for Single Shot Detector, is the system’s architecture, and it consists of a single neural network that predicts the image’s objects and their position during the same shot. And while this makes the model a speedy one, its accuracy performance is not as good as that of other models.

Then, there’s MobileNets, a class of efficient and light models suitable for object detection applications deployed on mobile devices (hence the name), and other low-resource platforms like embedded systems (think of tiny and cheap computers). Within this architecture, MobileNet plays the role of the feature extractor, which is the part of the system that extracts the details from the regions that might contain an object.
Lastly, there’s COCO (Common Objects in Context), which besides being “coconut” in Spanish, it’s the name of the dataset used to train the model. As its names indicate, COCO consists of 80 everyday objects one usually sees or finds around. For example, a person, airplane, apple, bottle, cow, and so on. Nevertheless, as impressive as 80 objects sound in the video I’m about to present, you will mostly see the same ones (after all, we don’t typically see cows and snowboards in every corner). Meaning that either the video had many things not present in the dataset, or it couldn’t detect most of them.
Below you’ll find the video. It’s a bit long, so feel free to skim around it. I’ll see you in a minute.
What did you think? How was the music? Let’s take a look at some of the most interesting cases.
In this screenshot from one of the first frames, we can see a stack of fruits where only two apples are detected. The sad part is that COCO contains orange and a banana label, and while I accept missing or mislabeling oranges, the same can’t be said about bananas. I mean, come on! It’s a banana!

I like this one. Even though there are around 7 million bikes on this scene, the model can handle most of them, and with a reasonable and quite acceptable confidence score (most of them are in the high ’60s and ’70s percent) too.

This scene is another of my favorites. Here we can see the model doing what it knows best from a moving car, an awful image quality, and a very unstable video. (Remember my earlier remark about how fast the model? This gif proves it).

This one is funny. For starters, these are masseur fishes that eat your dead skin, but only if you dare to put your legs inside the tank. But you know what’s even funnier? That these aren’t fishes. No, according to the magic of AI, some of them are carrots. What a miracle.


These are not umbrellas. Never. The curious thing here is that for about one or two frames (hard to see it in the gif), one of the bags is labeled as “handbag,” (which is correct) but as I approach them, they turned into umbrellas and even ties.

Most of the predictions we’ve seen here have the same labels: person, motorcycles, carrots, umbrellas, and so on. But this is not the whole story. Since I knew I was going to get curious about the specific detected objects, I modified the Android program and added a small functionality that logs and write to a file all the detected objects, and their count. For keep this post brief and simple I won’t explain the process, but I’ll link the repo with the modified code, and leave the explanation for another article. Now, with the files at hand, it was just a matter of reading them from R, performing a simple group by and find out the final tally.
In total, across all my footage, the model performed 3698 detections and found 29 unique objects. Of these predictions, 1611 (43.6%) of them were “car” (I didn’t show much of them, though), 1309 (35.4%) “person,” 327 (8.84%) “potted plant,” and 180 (4.87%) “motorcycle.” On the lower end, there was 1 (0.027%) “bottle,” “bowl,” “keyboard,” “kite,” and “oven.” The following two graphs present this information.
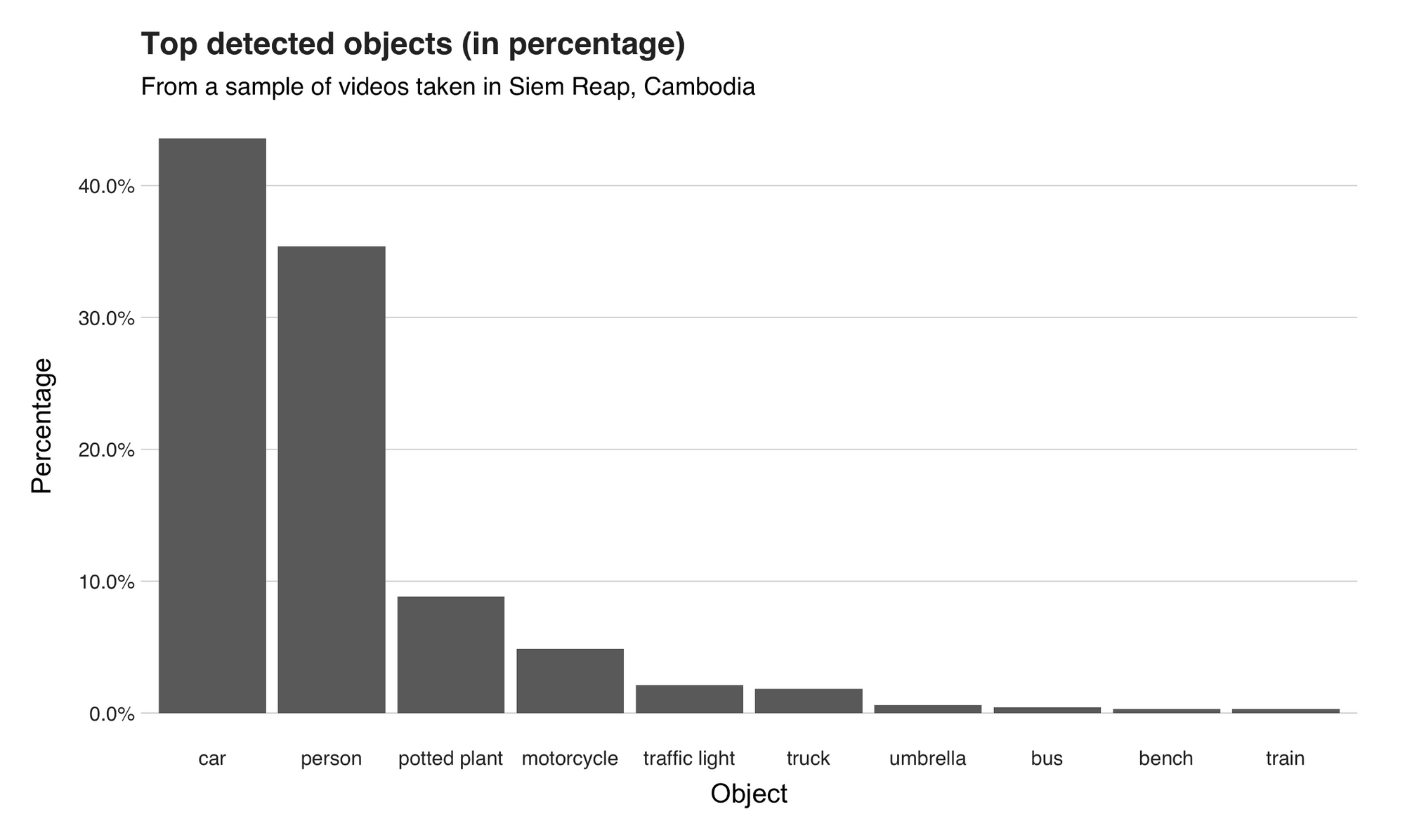
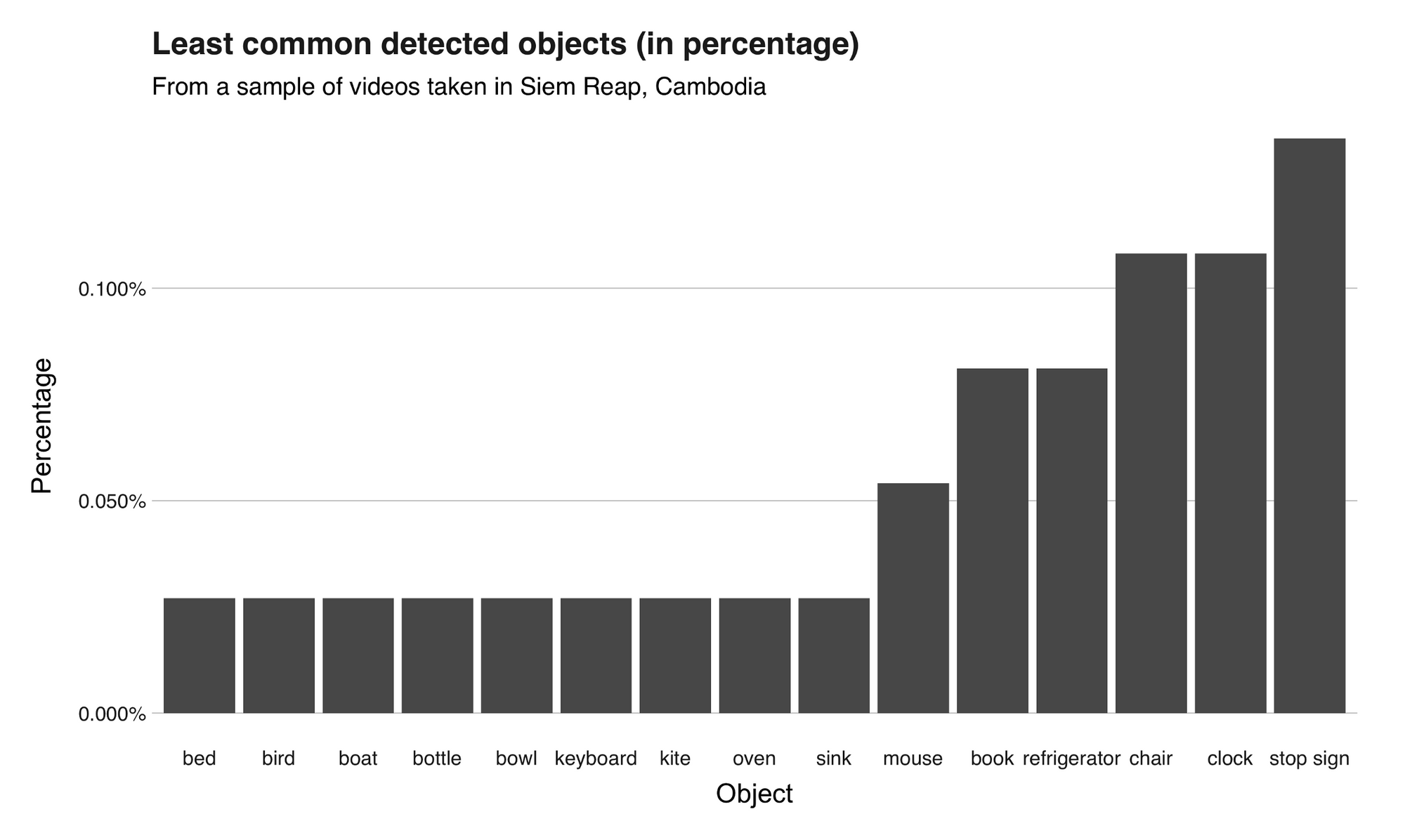
Recap and conclusion
In this article, I showed the lovely city of Siem Reap through the eyes of an object detection system deployed on an Android phone. During this tour, we experienced the city’s carrots, motorcycles, and plants that sometimes didn’t look that “planty.” In overall, I’m satisfied with the results. If we consider the settings and their conditions (non-stable camera, low resolution, me trying to avoid people), I’d say that the algorithm performed accurately. Sure, there were some hiccups, but that’s part of it :). In the future (I’m pretty sure I’ll do this again), I’d like to try different models since I got the impression this one runs pretty comfortable on my phone.
Lastly, I want to say that I have nothing against “PowerPoint AI.” We’ve all being there. I’m pretty sure that most of the well-known systems were born from a presentation or even more dramatic, from a napkin.
Thanks for reading.
The repository containing the project’s code is available here: https://github.com/juandes/wanderdata-scripts/tree/master/object_detection/siem-reap
This article is part of my Wander Data series, in which I’m telling and reliving my travel stories with data. To see more of the project, visit wanderdata.com.
![]()
Wander Data